Please note: Most, if not all, of the articles published at this website were completed by Chat GPT (chat.openai.com) and/or copied and possibly remixed from other websites or Feedzy or WPeMatico or RSS Aggregrator or WP RSS Aggregrator. No copyright infringement is intended. If there are any copyright issues, please contact: bicycledays@yahoo.com.
When you use AI instruments repeatedly, you need to’ve had this simple realisation – nobody device is ideal for all duties. Whereas some lead the pack when it comes to content material manufacturing (like ChatGPT), there are others which are means higher at producing pictures and movies (like Gemini). With such particular use-cases, we’ve seen a horde of AI instruments flood the market. Now, Alibaba’s Qwen plans to problem this scattered AI-tool-pool with its all-new Qwen3-Omni.
How? The Qwen group introduces Qwen3-Omni as a brand new AI mannequin that understands textual content, pictures, audio, and even video in a single seamless move. Furthermore, the mannequin and replies in textual content or voice in actual time, consolidating all use-cases in a single, seamless dialog. It’s quick, open supply, and designed to work like a real all-rounder. Briefly, Qwen3-Omni desires to finish the compromises and produce one mannequin that does all of it.
However does it do this? We strive it out right here for all its claims. Earlier than that, let’s discover what the mannequin brings to the desk.
What’s Qwen3-Omni?
For these unaware, the Qwen household of enormous language fashions come from the home of Alibaba. Qwen3-Omni is its newest flagship launch, constructed to be “really multimodal” in each sense. With that, the corporate mainly implies that the Qwen3-Omni doesn’t simply course of phrases, but additionally understands pictures, audio, and video, whereas producing pure textual content or speech again in actual time.
Consider it as a single mannequin that may advocate a pasta dish in French, describe a music monitor’s emotion, analyze a spreadsheet, and even reply questions on what’s taking place in a video clip, all with out switching instruments.
As per its launch announcement, what units Qwen3-Omni aside is its deal with pace and consistency. As a substitute of including separate plug-ins for various media varieties, the mannequin has been educated to deal with every thing natively. The result’s a system that feels much less like “textual content with add-ons” and extra like an AI that sees, hears, and talks in a single steady move.
For researchers and companies, this unlocks new prospects. Buyer assist brokers can now see product points through pictures. Tutoring methods can hear and reply like a human. Productiveness apps can now mix textual content, visuals, and audio in methods older fashions couldn’t handle.
Key Options of Qwen3-Omni
Apart from its multimodal design, Qwen3-Omni additionally stands out for its pace, versatility, and real-time intelligence. Listed below are the highlights that outline the mannequin:
Really multimodal: Processes textual content, pictures, audio, and video seamlessly.
Actual-time responses: Delivers on the spot outputs, together with lifelike voice replies.
Multilingual capacity: Helps dozens of languages with fluent translation.
Audio reasoning: Understands tone, emotion, and context in speech or music.
Video understanding: Analyzes shifting clips, not simply static pictures.
Open supply launch: Out there freely for builders and analysis.
Low-latency design: Optimized for quick, interactive purposes.
Constant efficiency: Maintains energy throughout textual content and multimodal duties.
Versatile deployment: Can run on cloud or native methods.
Enterprise-ready: Constructed for integration into apps, brokers, and workflows.
How Does Qwen3-Omni Work?
Most AI fashions add on new expertise as further modules. That’s precisely why some methods chat effectively, but wrestle with pictures, or course of audio however lose context. Qwen3-Omni takes a unique route, adopting a brand new Thinker–Talker structure that’s particularly designed for real-time pace.
The mannequin combines 4 enter streams: textual content, pictures, audio, and video right into a shared area. This enables it to cause throughout codecs in a single move. As an example, it could possibly watch a brief clip, hear the dialogue, and clarify what occurred utilizing each visuals and sound.
One other key function is low-latency optimization. Qwen’s group engineered the system for fast responses, making conversations really feel pure, even in voice. This is the reason Qwen3-Omni can reply mid-sentence as an alternative of pausing awkwardly.
And since it’s open supply, builders and researchers can see how these mechanisms work and adapt them into their very own apps.
Qwen3-Omni Structure
At its core, Qwen3-Omni is powered by a brand new Thinker–Talker structure. The Thinker generates textual content, whereas the Talker converts these high-level concepts into pure, streaming speech. This break up design is what allows the mannequin to talk in actual time with out awkward pauses.
To strengthen its audio understanding, the system makes use of an AuT encoder educated on 20 million hours of knowledge, giving it a deep grasp of speech, sound, and music. Alongside this, a Combination of Specialists (MoE) setup makes the mannequin extremely environment friendly, supporting quick inference even beneath heavy use.
Lastly, Qwen3-Omni introduces a multi-codebook streaming method that enables speech to be rendered body by body, with extraordinarily low latency. Mixed with coaching that mixes unimodal and cross-modal knowledge, the mannequin delivers balanced efficiency throughout textual content, pictures, audio, and video, with out sacrificing high quality in anyone space.
Qwen3-Omni: Benchmark Efficiency
A number of evaluations have been finished to check Qwen3-Omni throughout main benchmarks. Right here is the abstract:
MMLU (Large Multitask Language Understanding): Measures data throughout 57 topics. Qwen3-Omni scores 88.7%, outperforming GPT-4o (87.2%) and Gemini 1.5 Professional (85.6%).
MMMU (Large Multitask Multimodal Understanding): Checks college-level visible problem-solving throughout textual content and pictures. Qwen3-Omni achieves 82.0%, forward of GPT-4o (79.5%) and Gemini 1.5 Professional (76.9%).
Math (AIME 2025): Competitors-level math drawback fixing. Qwen3-Omni information 58.7%, stronger than GPT-4o (53.6%) and Claude 3.5 Sonnet (52.7%).
Code (HumanEval): Programming completion duties. Qwen3-Omni reaches 92.6%, surpassing GPT-4o (89.2%) and Claude 3.5 Sonnet (87.1%).
Speech Recognition (LibriSpeech): Evaluates computerized speech recognition. Qwen3-Omni hits 1.7% WER (phrase error price), matching Gemini 2.5 Professional and beating GPT-4o (2.2%).
Instruction Following (IFEval): Measures the accuracy of following pure language directions. Qwen3-Omni achieves 90.2%, exceeding GPT-4o (86.9%) and Gemini 1.5 Professional (85.1%).
Alongside these, Qwen3-Omni reveals sturdy outcomes on further exams like VQA-v2 for imaginative and prescient query answering and MOS-X for speech high quality. Collectively, these outcomes place it among the many most succesful open-source multimodal fashions to this point.
Qwen3-Omni: Easy methods to Entry
Qwen3-Omni is already out there by Qwen’s official platform and API endpoints, making it simple for builders and enterprises to start out experimenting in the present day.
Right here’s how one can strive it out:
On the Net: Go to the Qwen official web site, sign up, and choose Qwen3-Omni to start out producing textual content, pictures, or movies immediately within the browser.
Through API: Entry the mannequin by ModelScope or Hugging Face, the place APIs and documentation are offered for builders.
Enterprise Entry: Use Qwen3-Omni on Alibaba Cloud for scalable infrastructure and enterprise-level assist.
Qwen3-Omni: Fingers-on
I attempted the brand new Qwen3-Omni to check its capabilities throughout all its claims. Listed below are the exams I put it by and the outcomes it was in a position to ship.
1. Textual content Era
The go-to use case for any AI mannequin, I attempted Qwen3-Omni’s textual content era capacity utilizing the next immediate.
Immediate:
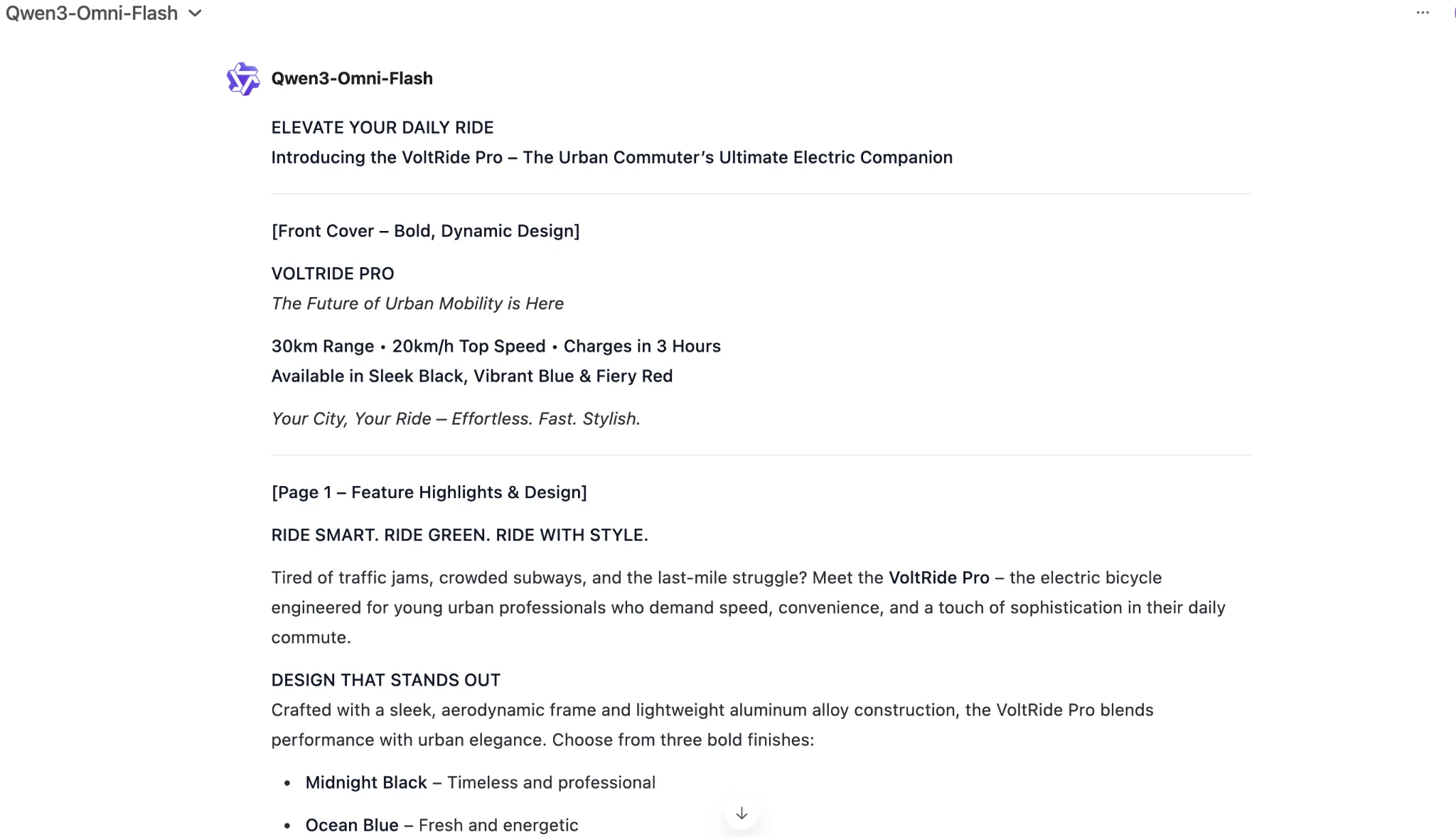
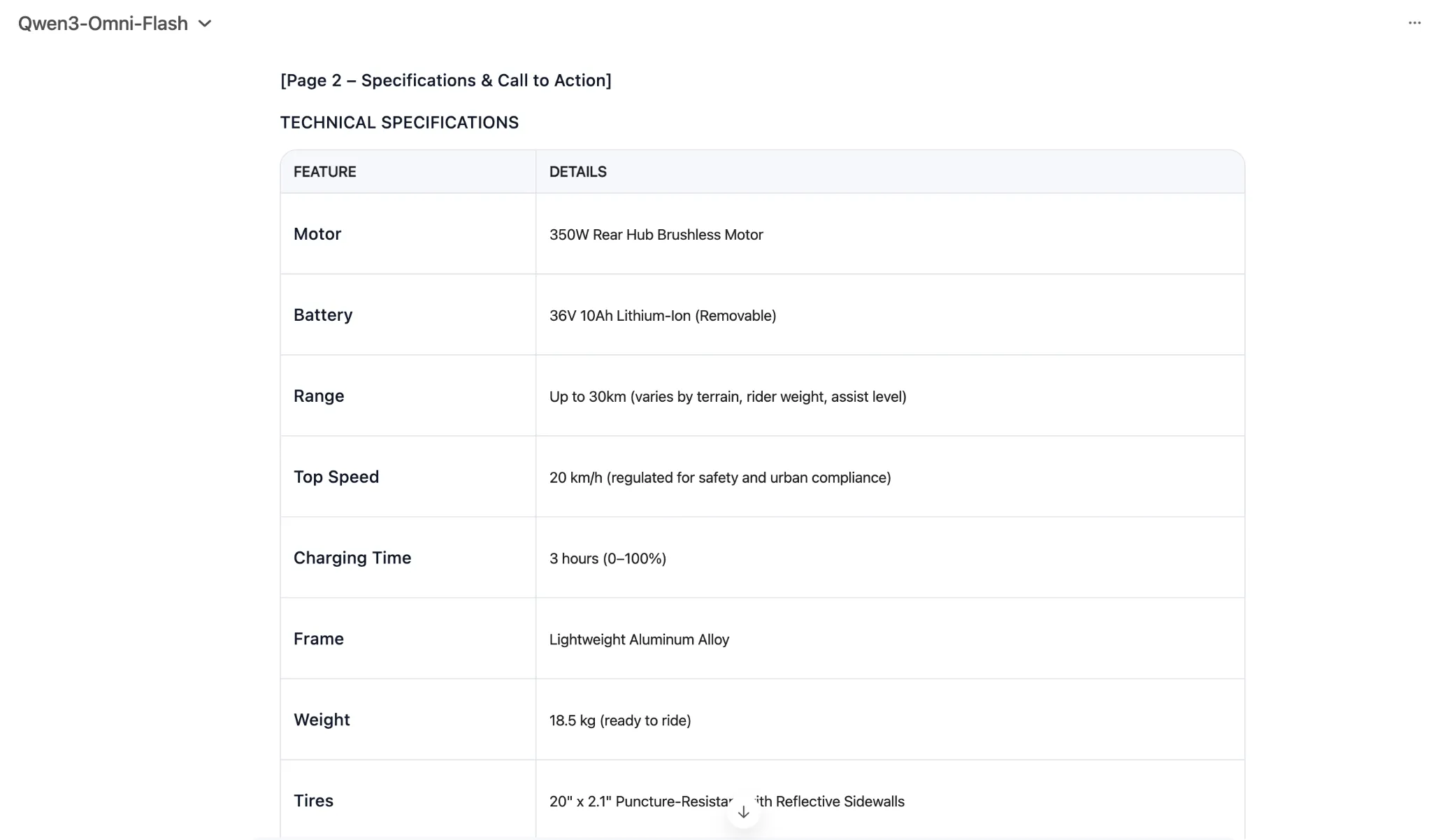
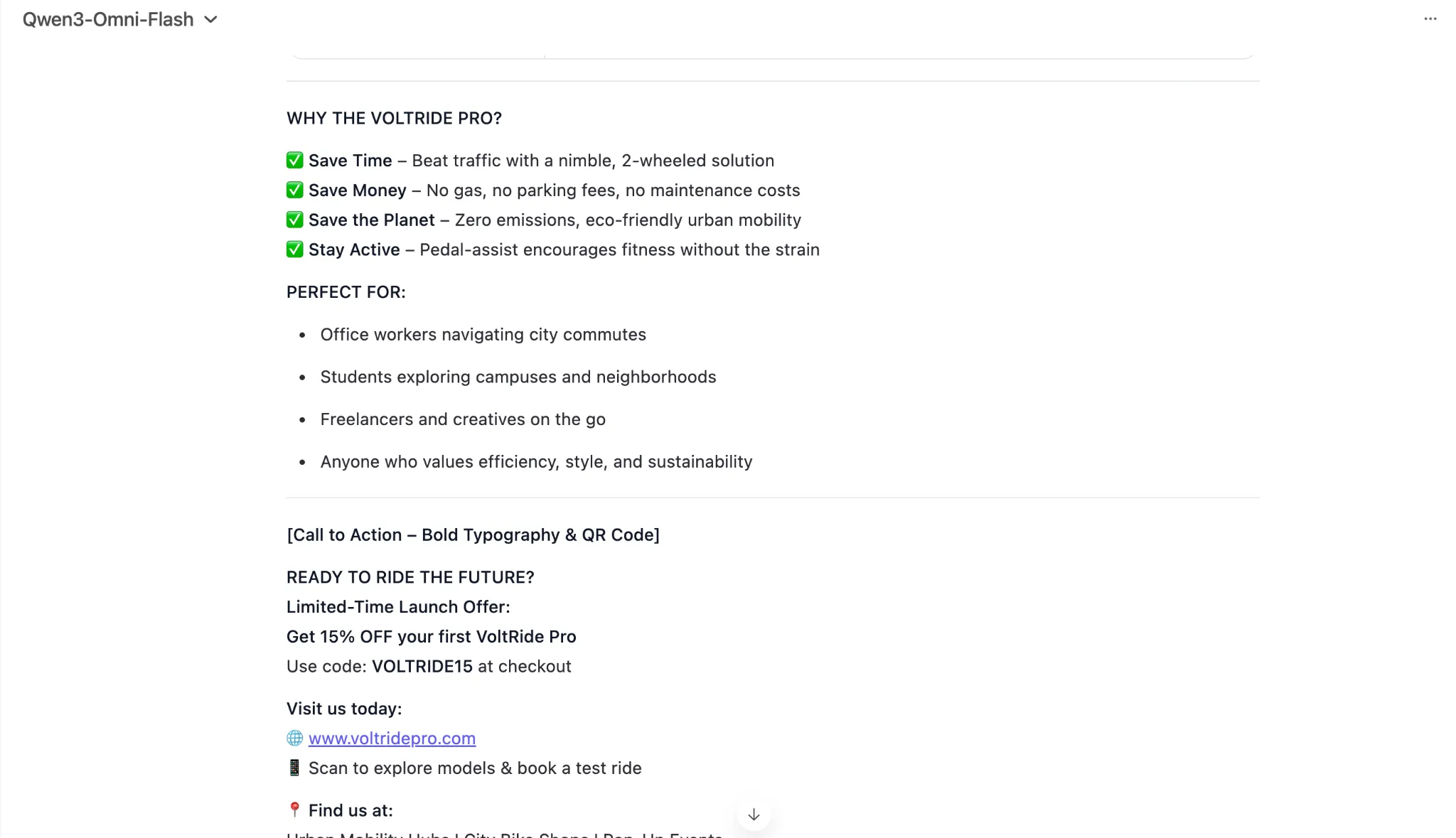
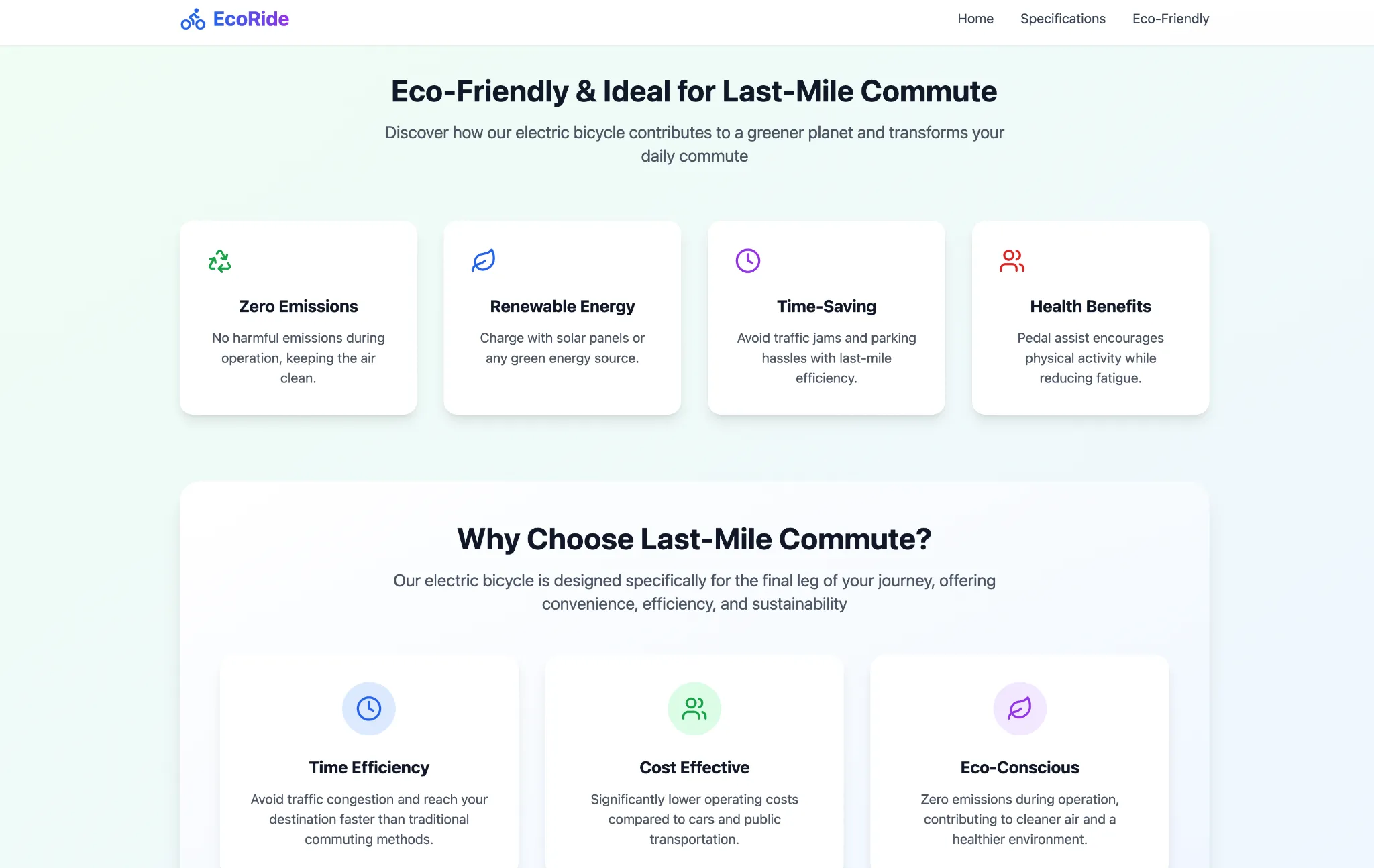
Generate textual content for an elaborate 2-page printable magazine-style flier for an electrical bicycle. The bicycle is available in three colors – black, blue, and crimson. It has a variety of 30kms per cost and a high pace of 20 kms. It expenses in 3 hours. Think about all different mandatory data and specs.
Be certain that to focus on all of the options of the e-bike throughout the flier, and introduce it to the lots in as interesting method as doable. target market – younger professionals in city settings on the lookout for a last-mile connectivity resolution.
Output:
Qwen3-Omni textual content era
Qwen3-Omni textual content era
Qwen3-Omni textual content era
Qwen3-Omni textual content era
As you may see, the newest Qwen AI mannequin was fairly on-point with the duty at hand, producing a near-perfect response in precisely the format one would envision for a product flier. 10 on 10 to Qwen3-Omni for textual content era right here.
2. Picture Era
Subsequent comes the take a look at for picture era. Also, to check its claimed omni-modal functionality, I adopted as much as the sooner immediate with a picture era process.
Immediate:
are you able to create the entrance cowl you point out within the product description above? Make it catchy, with vibrant colors, and present all three color variations of the e-cycle stacked aspect by aspect
Output:
As you may see, the brand new Qwen3 mannequin was in a position to produce a super-aesthetic picture following the immediate to accuracy. A small element it missed out on was the color of one of many bikes, which was speculated to be Pink, as an alternative of Orange, as proven right here. But, the general output is kind of pleasing, and it earns my advice for picture era.
A Massive Observe: To generate a picture on Qwen3-Omni, even throughout the similar chat window, you’ll have to click on on the “Picture Era” possibility first. With out this, it should merely generate a immediate for the picture, as an alternative of an precise picture. This beats the entire goal of it being a seamless workflow inside an “omni-modal”, as different instruments like ChatGPT provide.
A fair larger flaw right here: To return from the picture era window to another, you’ll have to begin a New Chat another time, dropping all of the context of your final chat. This mainly means Qwen3-Omni lacks massively on a seamless workflow that an all-encompassing AI device ought to observe.
3. Video Era
Once more, you’ll have to name the Video Era device in a chat window on the Qwen3-Omni, in order to make a video. Right here is the immediate I used and the next outcome I received.
Immediate:
generate an advert business of the electrical bicycle we mentioned earlier, exhibiting a younger boy zooming alongside metropolis roads on the e-bike. Present a couple of textual content tags alongside the video, together with “30Kms Vary” to focus on the e-bikes options. Preserve vibrant colors and make the general theme very catchy for potential patrons
Output:
As you may see, the video isn’t excellent, with a wierd, unrealistic move to it. The colors are washed out, there aren’t any particulars throughout the video, and the AI mannequin utterly did not induce textual content throughout the video precisely. So I wouldn’t actually advocate it for video era functions to anybody.
4. Coding
To check the coding talents of the brand new Qwen3 mannequin, right here is the immediate I used and the outcome it delivered.
Immediate:
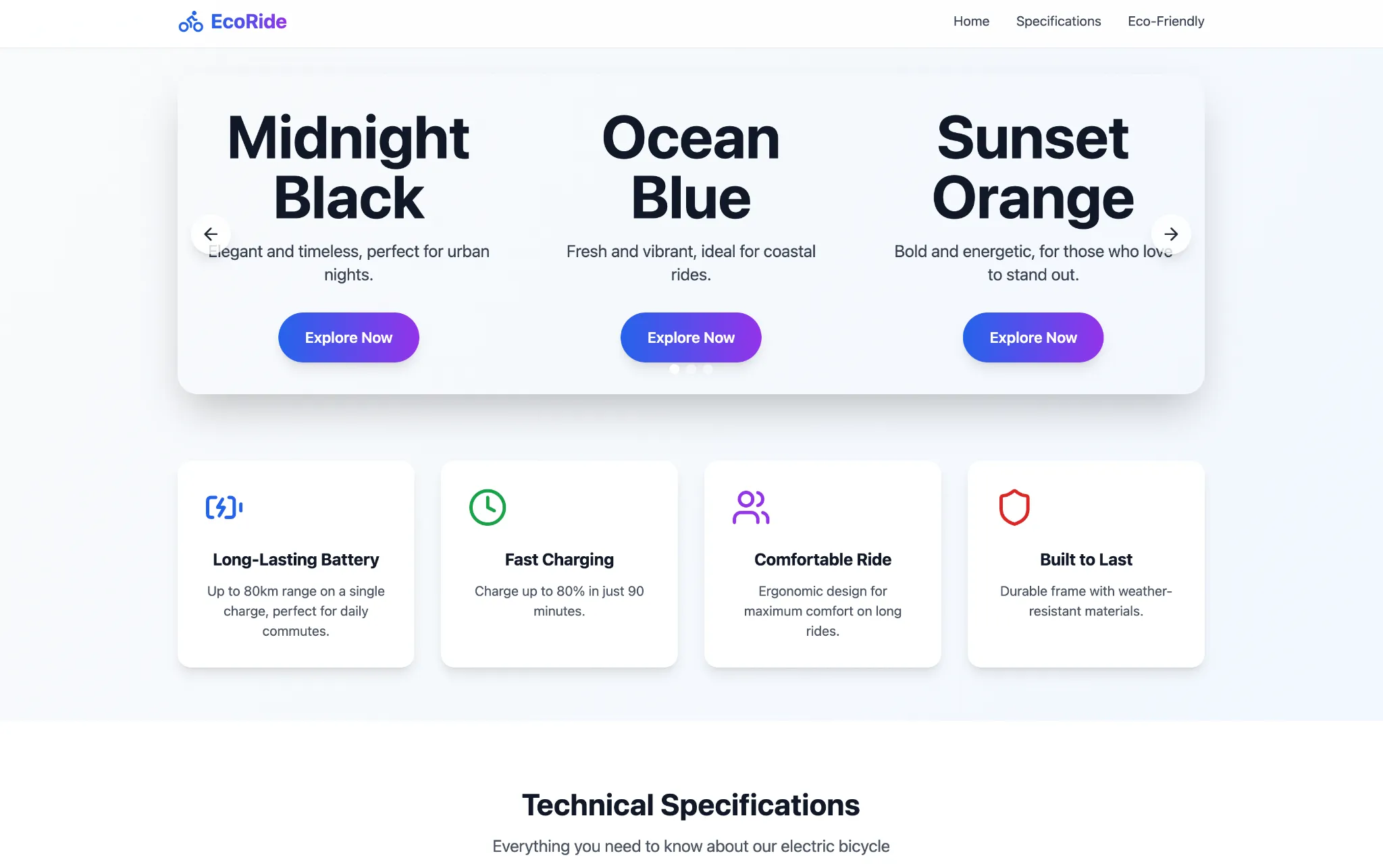
please write a code for a 3-page web site of the electrical bicycle we’ve got mentioned in different chats. ensure to showcase the three colors in a carousel on the residence web page. maintain one web page for product specs and the third one for a way the e-bike is eco pleasant and ultimate for final mile commute
Output:
It appears to have finished a part of the work on the web site, having created the asked-for pages but nothing inside them. Although no matter it got here up with, the Qwen3-Omni did job when it comes to aesthetics and performance of the web site, which appears to be like fairly pleasing general. Takeaway – it’s possible you’ll want to be extremely particular together with your prompts when utilizing Qwen3-Omni for internet growth.
Conclusion
It’s clear that Alibaba’s Qwen group has made one of many boldest steps but in multimodal AI. From the Thinker–Talker structure that permits real-time streaming speech, to the AuT audio encoder educated on 20 million hours of knowledge, the mannequin’s design clearly focuses on pace, versatility, and stability throughout modalities. Benchmark outcomes again this up: the brand new Qwen3 mannequin persistently outperforms rivals throughout duties like MMLU, HumanEval, and LibriSpeech, exhibiting it’s not simply an open-source launch however a severe contender within the AI race.
That mentioned, the hands-on expertise reveals a extra nuanced image. On core talents like textual content and picture era, the brand new AI mannequin delivers extremely correct, inventive outputs, even when it often misses high quality particulars. However its greatest flaw is workflow: switching between textual content, picture, and video modes requires beginning contemporary chats, breaking the “seamless omni-modal” promise. In different phrases, Qwen3-Omni is highly effective and spectacular, however not but good. And there could be some time earlier than it actually achieves what it has set out for.
Technical content material strategist and communicator with a decade of expertise in content material creation and distribution throughout nationwide media, Authorities of India, and personal platforms
Login to proceed studying and revel in expert-curated content material.


{kind=link}





