Synthetic intelligence is quickly evolving. New fashions emerge practically every single day, with each making an attempt to be the most effective. On this sea of comparable fashions, we see one thing new every so often. One in every of such fashions is the brand new Mistral Small 4. It’s an progressive AI mannequin that isn’t solely going to be one other selection within the plethora of AI fashions, but in addition makes an attempt to be the mannequin of your selection. No extra multi-modeling on hatting, coding, and multifaceted considering. Mistral Small 4 packages them right into a single formidable and efficient mannequin.
It’s not nearly comfort. Mistral Small 4 applies the Combination-of-Consultants (MoE) intelligent design to present the efficiency of a 119-billion-parameter mannequin, however runs at a fraction of the ability required to execute anybody process. This means that it’s fast, low cost, and even picture discerning. On this information, we are going to dissect what makes Mistral Small 4 tick, the way it compares to the competitors, and we may also take you thru some real-life conditions wherein you need to use it.
What’s New With Mistral Small 4?
Mistral Small 4 is exclusive resulting from the truth that it incorporates three totally different capabilities into one single and easy mannequin. Beforehand, you can have had one AI to have a dialog, one other one to have interaction in analytical work, and a 3rd one to put in writing code. Mistral Small 4 is made to deal with all that effortlessly. It will possibly additionally function a common chat assistant, a coding skilled, and a reasoning engine, all around the similar endpoint.
Its Combination-of-Consultants (MoE) structure is the key of its effectivity – a bunch of 128 specialists. One other benefit of the mannequin is that it doesn’t require all of them engaged on the entire issues; as an alternative, the mannequin is wise sufficient to select the highest 4 to work on the given process. This means that the full variety of parameters within the mannequin is large (at 119 billion), however just a few, between 6 and 6.5 billion, shall be activated by a selected request. This makes it fast and lowers the price of operation.
The principle traits are the next:
- Multimodal Enter: It is aware of each photos and textual content, owing to its Pixtral imaginative and prescient ingredient.
- Lengthy Context Window: This has the flexibility to deal with as much as 256,000 tokens of data at a time therefore it’s relevant within the evaluation of lengthy paperwork.
- Open and Accessible: The weights of the mannequin are underneath Apache 2.0 license, which allows industrial use. It’s open-source and works by way of APIs and associate platforms.
- Efficiency Optimised: Mistral boasts of a 40 p.c lower within the period of time taken to finish and three occasions extra requests per second than its predecessor.
Below the Hood: Structure and Specs
Mistral Small 4 is a mix of a textual content decoder and a imaginative and prescient encoder. On giving a picture, the Pixtral imaginative and prescient system interprets the picture and passes the data over to the textual content mannequin that then produces a response. Such a design permits it to mix with visible data and textual prompts.
The next are a number of the architectural particulars:
- Decoder Stack: 36 transformer layers, hidden measurement of 4096, and 32 consideration heads.
- MoE Particulars: 128 specialists, 4 of that are activated per token, with a shared skilled element in order that issues are constant.
- Imaginative and prescient Element: The Pixtral imaginative and prescient mannequin incorporates 24 layers and pictures with a patch measurement of 14.
- Vocabulary: The mannequin has a Tekken tokenizer with a wealthy vocabulary of 131,072 tokens to allow help for a couple of language and complex directions.
Though the variety of lively parameters is low, the general measurement of the mannequin determines the reminiscence necessities. The parameter mannequin 119B has a big VRAM requirement; the 4-bit quantised model alone consumes round 60 GB, and a 16-bit model consumes nearly 240 GB. This doesn’t embody the reminiscence required within the KV cache of long-context duties.
Benchmarks and Analysis
Mistral Small 4 just isn’t merely a wise design; it has figures that may help its efficiency arguments. Mistral focuses on the standard and effectivity, the place the mannequin is able to delivering high-quality solutions in a really slim style. The ensuing low latency and low value in apply will be straight associated to this emphasis on shorter outputs.
Effectivity: Excessive Scores with Much less Discuss
On varied benchmarks, a constant pattern exists: Mistral Small 4 contributes to and even beats the state-of-the-art fashions utilizing loads fewer phrases to take action.
On Mathematical Reasoning (AIME 2025)
The rating of the mannequin in its reasoning mode is 93, which is the same as a lot greater Qwen3.5 122B. However its common size of output in instruct mode is barely 3,900 characters, which is a fraction of the virtually 15,000 characters of GPT-OSS 120B.
On Coding Duties (LiveCodeBench)
The mannequin has a aggressive rating of 64, marginally beating GPT-OSS 120B (63). It reveals effectivity: it produces code that’s greater than 10 occasions shorter (2.1k characters vs. 23.6k characters), because it is ready to produce appropriate code with out the pointless wordiness.
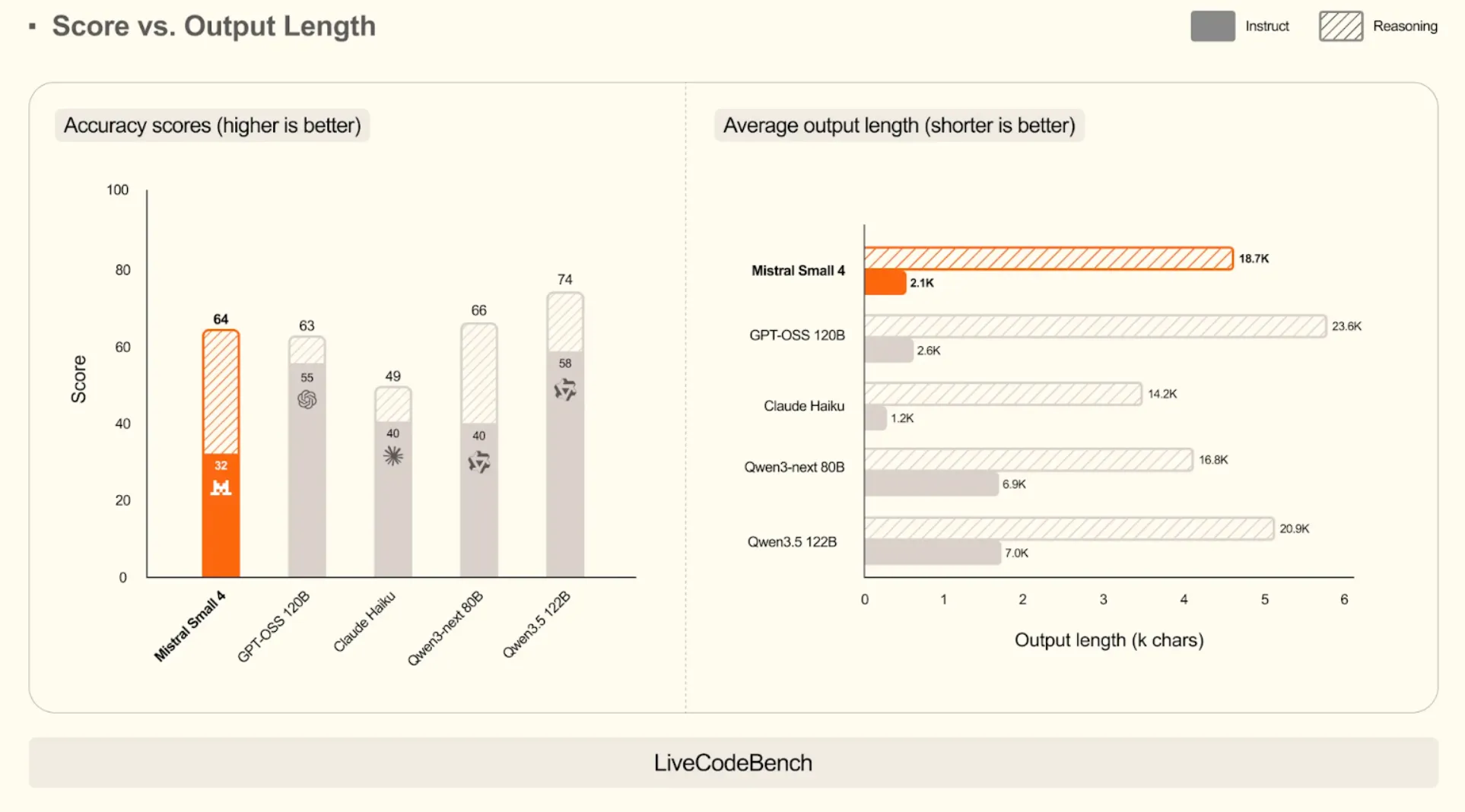
On Lengthy-Context Reasoning (LCR)
Mistral Small 4 will get a excessive score of 72. It does this at a particularly quick output of solely 200 characters in instruct mode. This is among the exceptional expertise of extracting solutions even within the huge volumes of textual content.
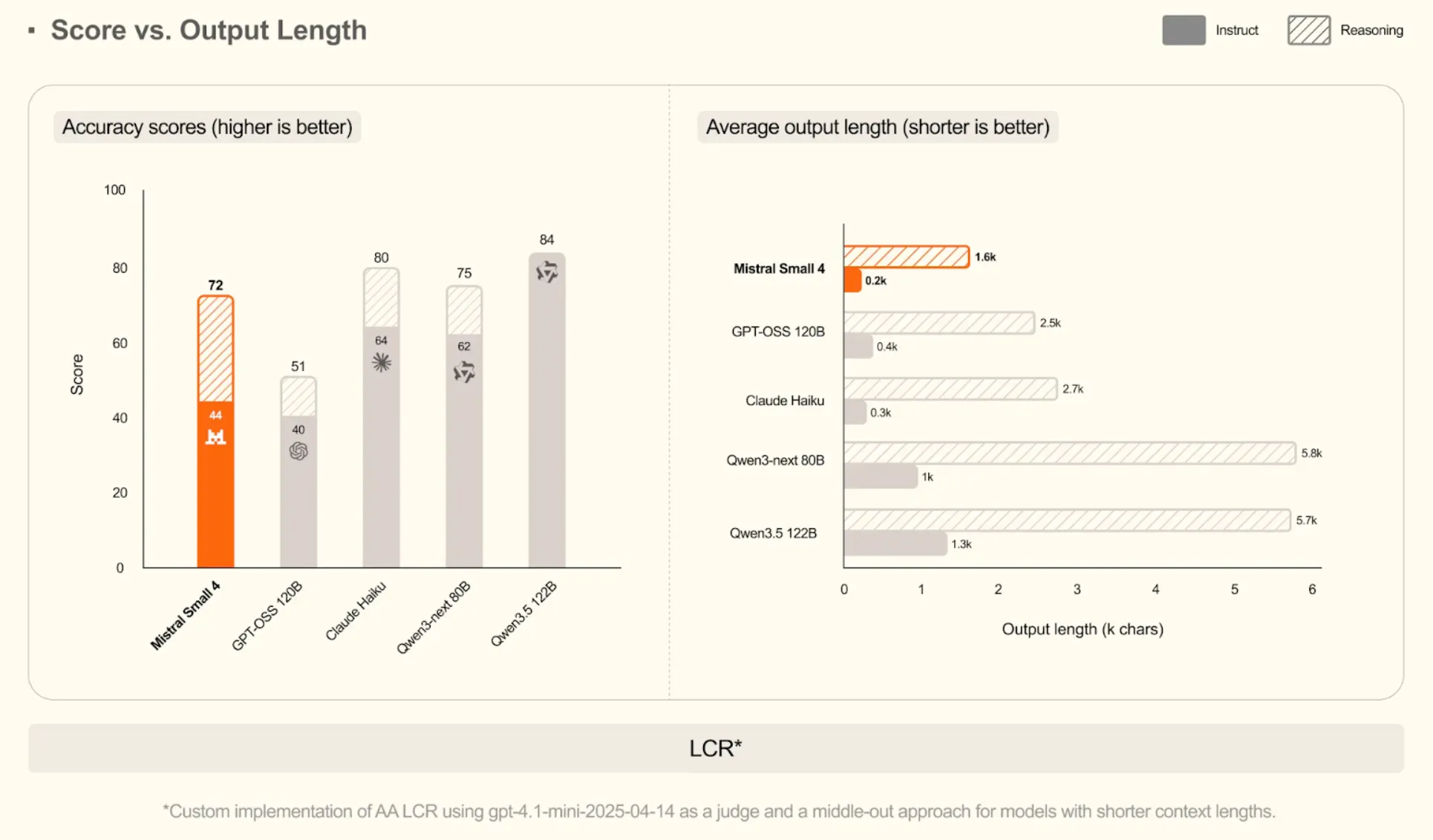
A Generational Leap for Mistral
Comparisons with the opposite fashions reveal that Mistral Small 4 is a big enchancment over the previous fashions. It repeatedly achieves new inner requirements on textual content and imaginative and prescient requirements.
- Increased Reasoning: It tops the Mistral fashions on tough textual content checks with a rating of 71.2 on GPQA Diamond and 78 on MMLU Professional.
- Imaginative and prescient Capabilities: The mannequin additionally performs higher in imaginative and prescient duties with a rating of 60 in MMMU-Professional, which is larger than the sooner fashions, similar to Mistral Small 3.2 and Medium 3.1.
-
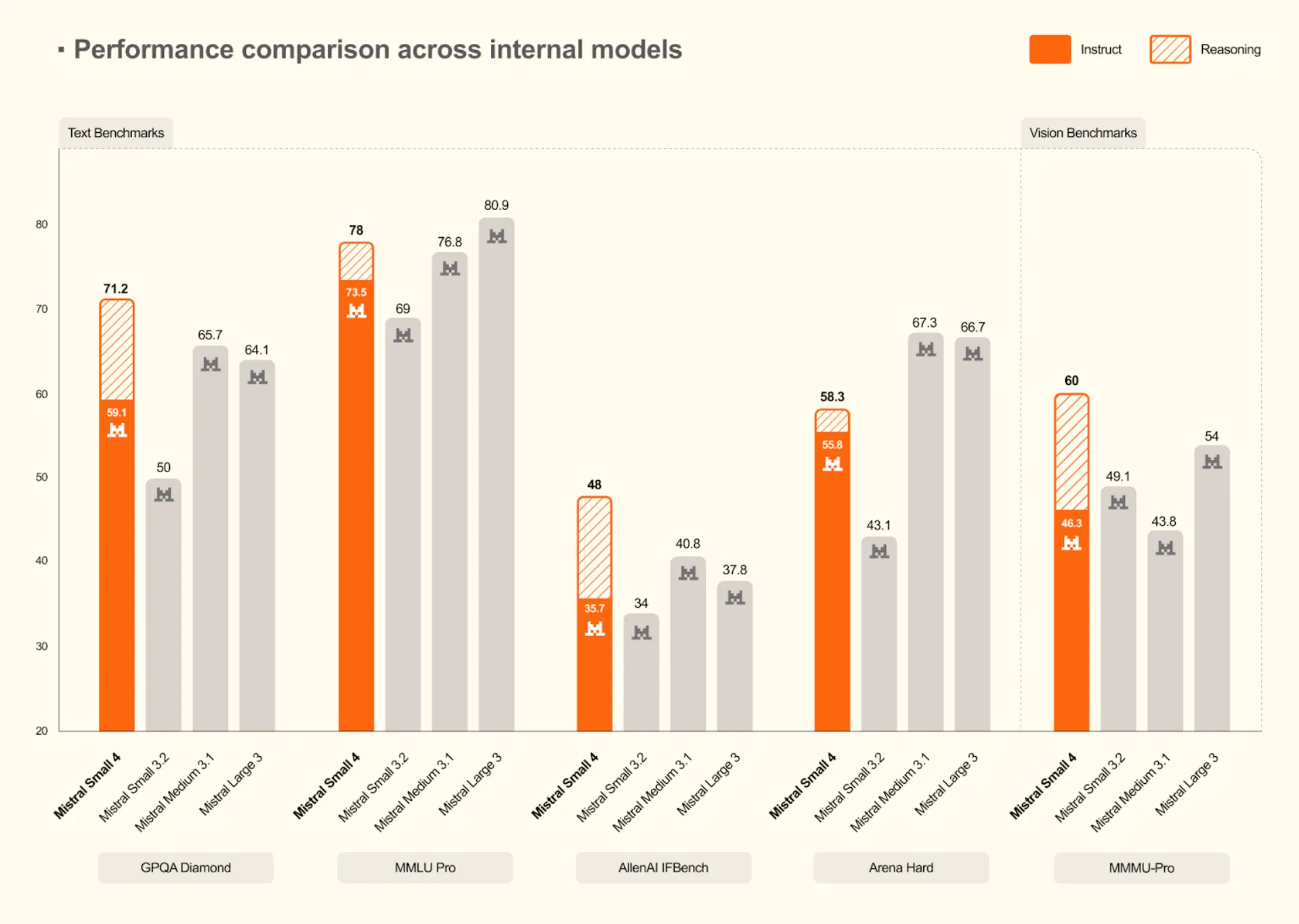
Supply: Mistral AI -
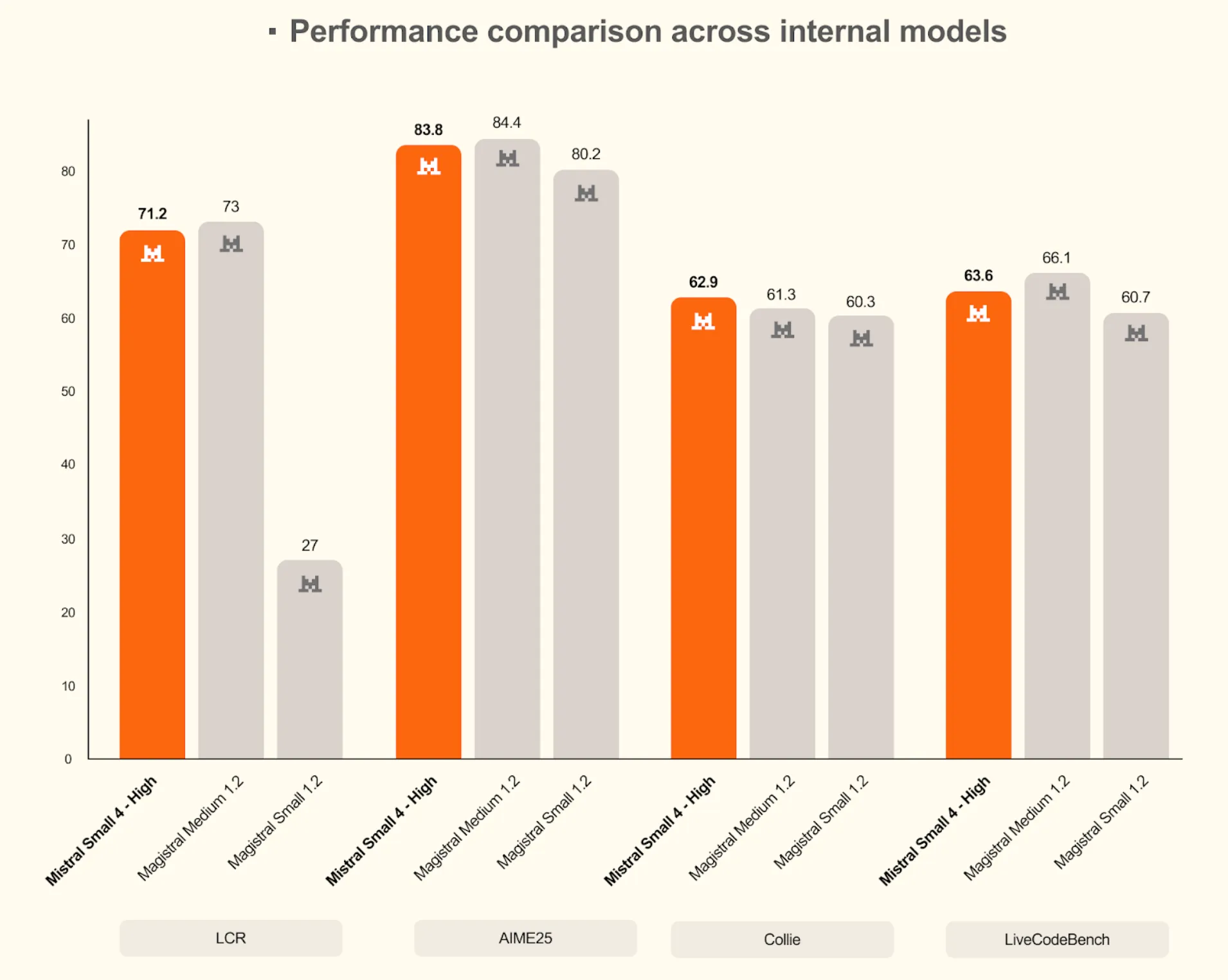
Supply: Mistral AI
Mistral Small 4 could be very aggressive with, and at occasions performs even higher than, bigger inner fashions similar to Magistral Medium 1.2 on difficult benchmarks when its high-reasoning mode is used. This reality helps the conclusion that Mistral Small 4 is as able to assembly its declare of providing the most effective in reasoning and coding expertise in a handy bundle.
Palms-on with Mistral Small 4: Sensible Duties
Earlier than palms on lets perceive find out how to entry the Mistral Small 4.
- First, go to https://console.mistral.ai/ and join utilizing your cellular quantity.
- Now head over to the “Playground”.
- Then choose the ‘Mistral Small Newest’ from the fashions listing.
- You might be prepared to make use of the mannequin.
Benchmarks and numbers inform a part of the story, however the easiest way to know a mannequin is to see it carry out. We examined Mistral Small 4 on three frequent, real-world duties to judge its reasoning, coding, and writing expertise.
Job 1: Structured Enterprise Reasoning
Goal: Check the mannequin’s capability to carry out calculations, establish dangers, and provide a strategic advice primarily based on enterprise knowledge—all whereas sustaining a structured and concise format.
Immediate:
You’re a product strategist.
A SaaS firm has three subscription tiers:
Primary: 12,000 customers at $5/month with 18% churn
Normal: 7,500 customers at $12/month with 9% churn
Premium: 2,000 customers at $25/month with 3% churn
Duties:
- Calculate month-to-month income for every tier
- Establish which tier is most in danger
- Advocate one strategic change
- Preserve the reply structured and concise
Output:
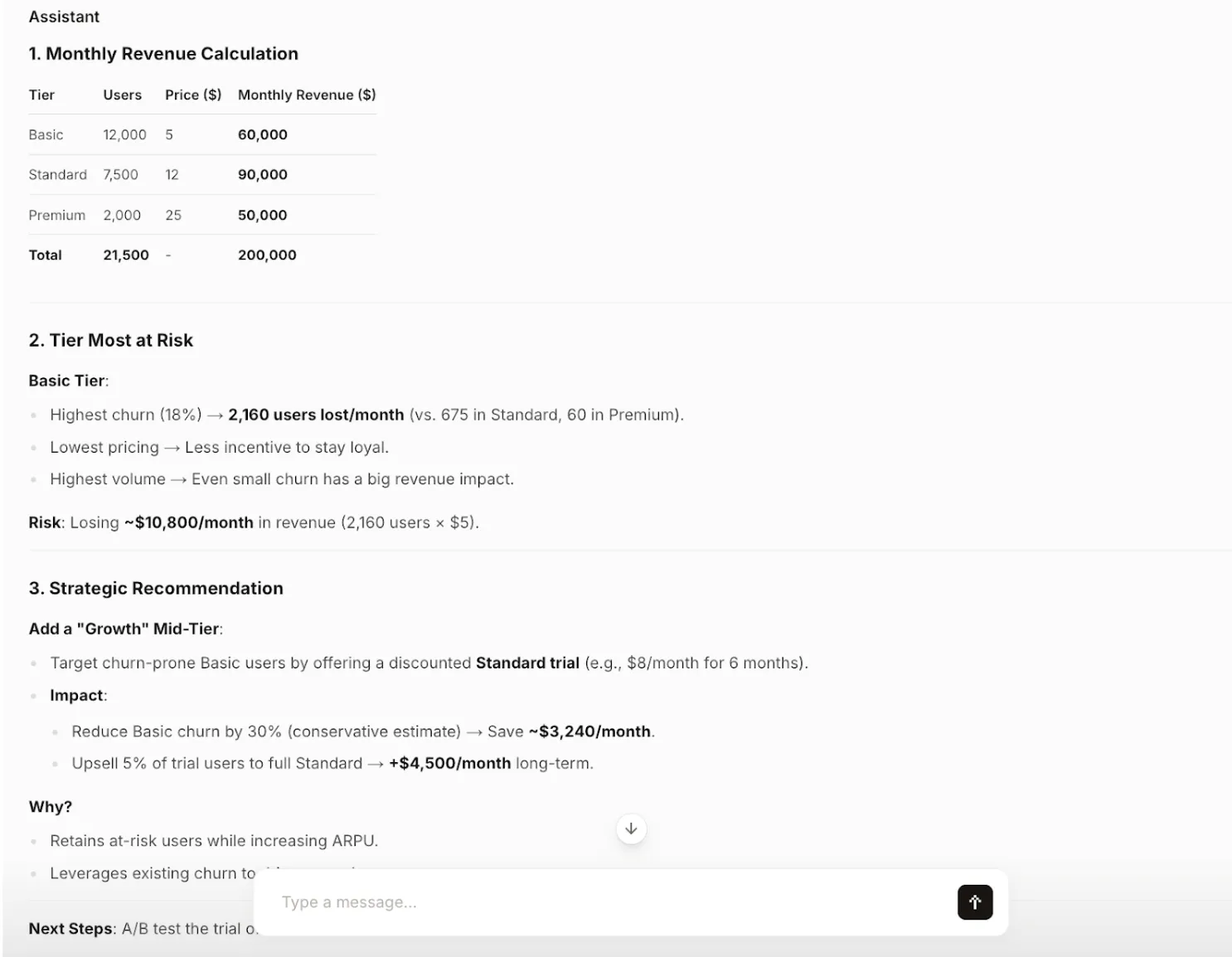
Evaluation: The mannequin accurately performs the calculations and identifies the Primary tier as the first danger resulting from its excessive churn charge. The strategic advice just isn’t solely artistic but in addition backed by clear, data-driven reasoning and contains actionable subsequent steps. The output is completely structured and concise, following all directions.
Job 2: Environment friendly and Clear Coding
Goal: Check the mannequin’s coding talents, particularly its capability to establish a logical bug, present a corrected and extra environment friendly answer, and counsel additional enhancements.
Immediate:
Repair the next Python perform and make it extra environment friendly.
def common(numbers):
complete = 0
for i in vary(len(numbers)):
complete += i
return complete / len(numbers)
Duties:
- Establish the bug
- Present corrected code
- Recommend one enchancment
Preserve the response concise and optimized.
Output:
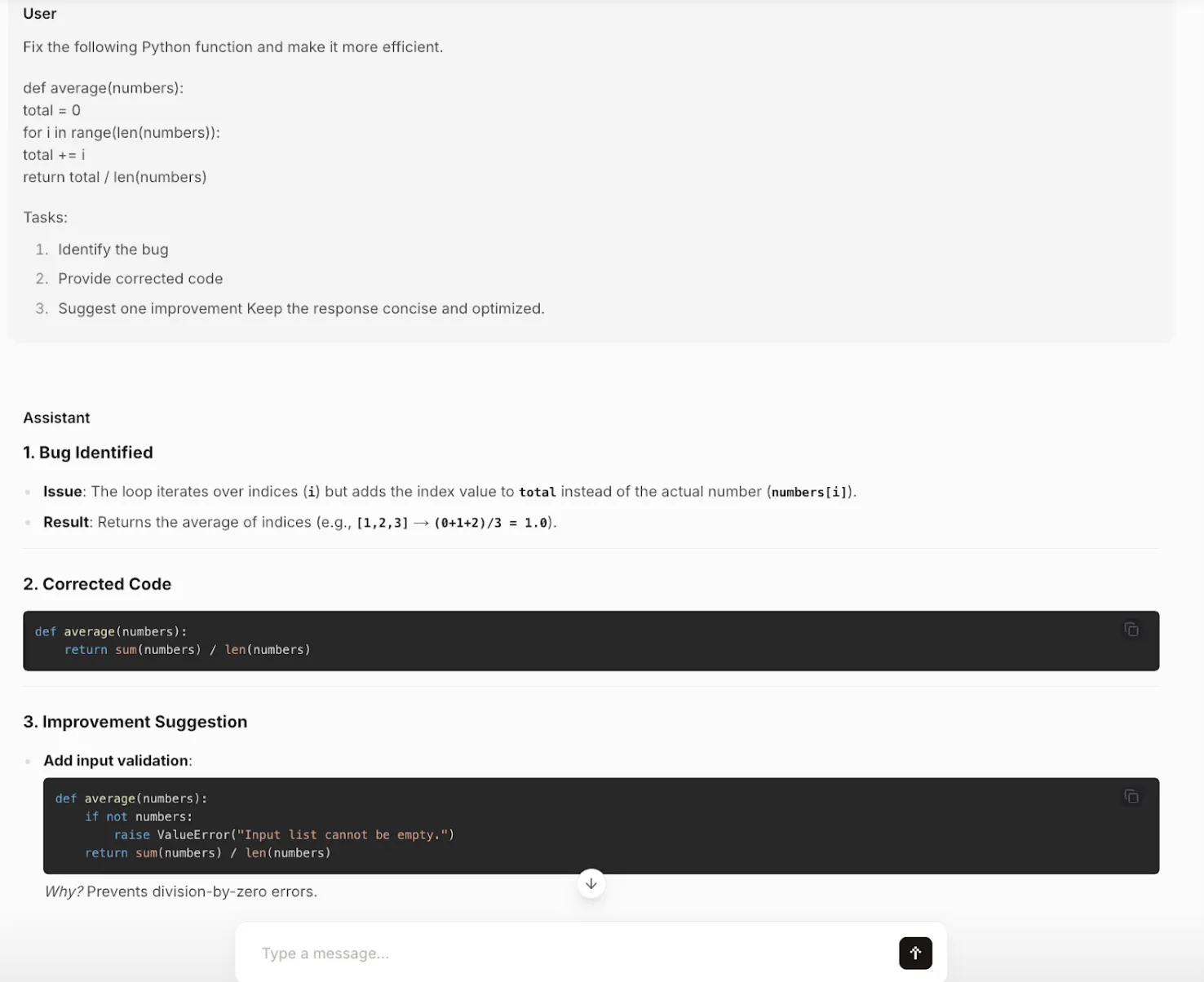
Job 3: Skilled E mail Writing
Goal: Check the mannequin’s real-world writing expertise by rewriting an off-the-cuff, barely aggressive e mail into an expert, well mannered, and clear message whereas adhering to a phrase depend.
Immediate:
Rewrite this e mail to be skilled, concise, and well mannered:
“Hey, simply following up on the dataset you mentioned you’d ship final week. We nonetheless don’t have it and it’s blocking our work. Also some recordsdata earlier had lacking columns. Are you able to verify that?”
Necessities:
- Preserve it underneath 120 phrases
- Keep a well mannered however agency tone
- Enhance readability
Output:
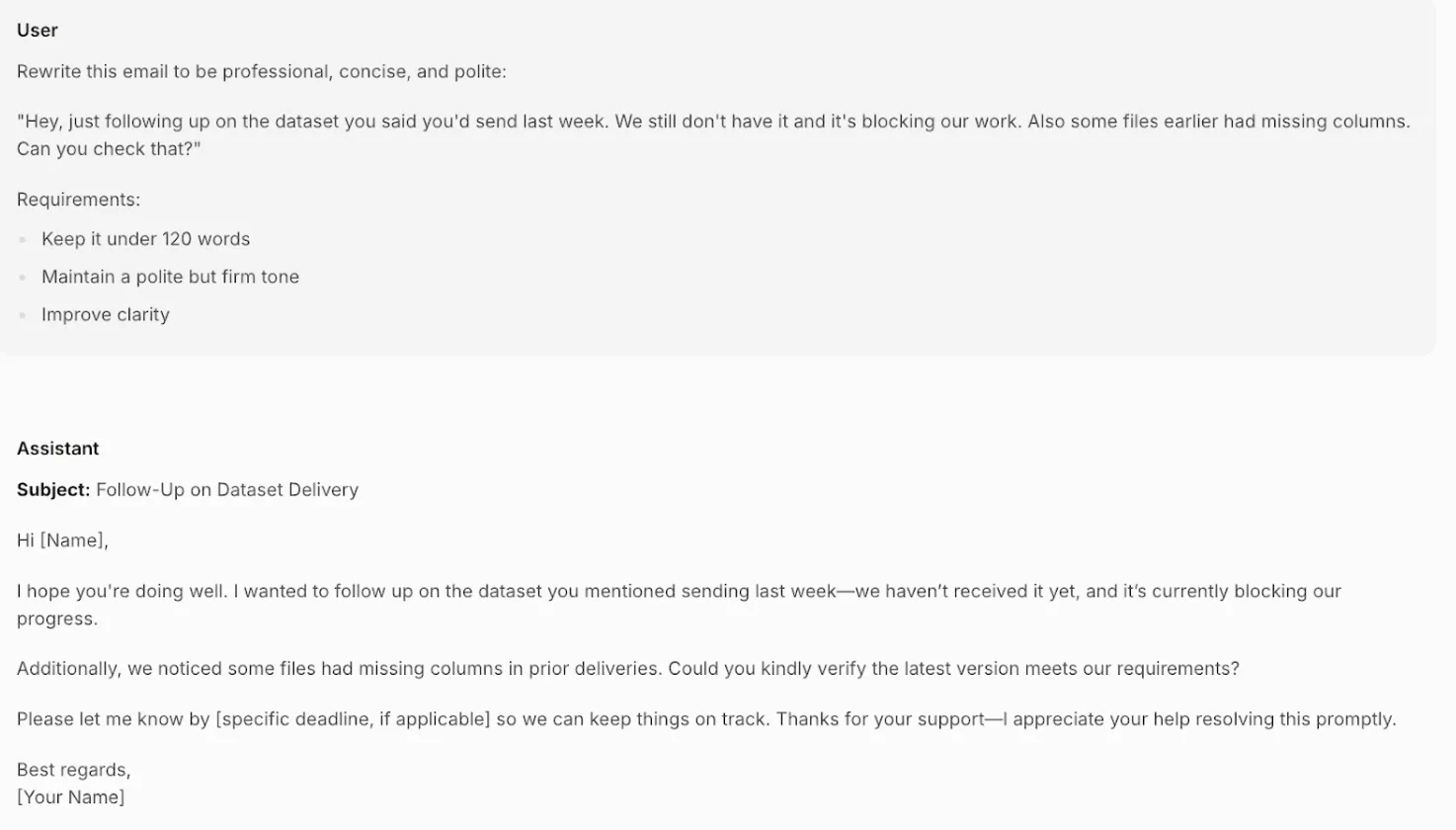
Evaluation: The mannequin transforms the unique message completely. It replaces the blunt, accusatory tone with an expert and well mannered one (“I hope you’re doing effectively,” “May you kindly confirm”). It clearly states the issue (blocked progress) and provides a placeholder for a deadline, making the request agency however respectful. The e-mail is effectively underneath the phrase restrict and demonstrates a nuanced understanding {of professional} communication.
How Does It Evaluate to Its Friends?
Mistral Small 4 will get into the aggressive market. This can be a transient overview of the efficiency comparability between it and different fashions within the parameter vary of roughly 120B.
- vs. GPT-OSS 120B: Mistral claims Small 4 as a straight rival, asserting that it’s as profitable as GPT-OSS on crucial metrics and generates shorter and extra environment friendly outcomes. This interprets to diminished latency and value in manufacturing.
- vs. Qwen3.5-122B-A10B: Each of those fashions are giant context home windows and high-performance oriented. The Apache 2.0 open license supplied by Mistral will be one of many the explanation why the enterprise will take into account it to have the correct of economic use.
- vs. NVIDIA Nemotron 3 Tremendous 120B: NVIDIA has been liable to offering detailed documentation on coaching knowledge on its base fashions. A person who values the openness of the coaching corpus might fall on the aspect of Nemotron, however Mistral offers extra particular recommendation on deployment {hardware}.
The thought right here is that though the lively parameters make the compute value per token smaller, they’re nonetheless giant fashions. In accordance with the {hardware} suggestions of Mistral itself, to run it productively in eventualities with lengthy context duties is a multi-GPU affair.
Conclusion
Mistral Small 4 is not only one other large mannequin. It’s a well-considered framework designed to handle a real-world subject, specifically the problem of managing a number of specialised AI fashions. It brings chat, reasoning, and coding collectively into one, environment friendly endpoint, and that could be a very enticing provide to the builders and companies. With good efficiency and multimodal capabilities together with its open-weights method, it’s a robust competitor within the AI world.
Though it doesn’t wave a magic wand to make using highly effective {hardware} pointless, its architectural efforts, in addition to its emphasis on output effectivity, are a considerable transfer in the direction of enchancment. To people who’re all for developing the superior but reasonably priced AI functions, Mistral Small 4 will definitely be a case to be adopted and to develop with.
Regularly Requested Questions
Its key energy is to combine the ability of a chat mannequin, a reasoning mannequin, and a coding mannequin in a single, environment friendly endpoint. This ensures simpler improvement and fewer overhead in operation.
Sure, its weights are launched underneath the Apache 2.0 license, which allows industrial use. This makes it a powerful choice for companies seeking to construct on an open-weight basis.
The minimal {hardware} instructed by Mistral is 4 H100 GPUs or comparable. They advocate a extra elaborate, disaggregated configuration within the case of high-throughput, long-context workloads.
Sure, it’s multimodal and is able to taking textual content enter and picture enter, the place its Pixtral imaginative and prescient stack would analyze the picture.
Mistral asserts to outperform and even exceed comparable fashions similar to GPT-OSS 120B on quite a few benchmarks, and has the added benefit of manufacturing shorter and extra environment friendly outputs, probably leading to diminished latency and value.
![]()
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.






{kind=link}