April has been a busy month on the earth of AI. Two main AI fashions, hailing from the largest AI corporations of immediately, noticed their debuts concurrently. Anthropic was the primary to drop Opus 4.7, and near comply with on its heels was OpenAI, which got here out with its GPT-5.5. Although the main fashions from their respective homes, each have been launched to differing reactions from their customers. Regardless, they declare to be the perfect AI brains of immediately, and that’s precisely what we’ll put to the take a look at right here.
On this article, we will examine the GPT 5.5 with Claude’s new Opus 4.7. We will take a look at each the fashions on their skills throughout use-cases, to search out the perfect match for various kinds of workflows individuals normally depend on AI for. So with none additional ado, let’s dive proper in.
Introduction to the Fashions
Allow us to start with a short introduction of each fashions for these unaware.
GPT-5.5
As talked about, GPT-5.5 is OpenAI’s newest mannequin, positioned as its smartest and most intuitive mannequin but. However past the standard launch adjectives, the actual shift appears to be in the way it handles work. This mannequin is particularly designed to know intent, plan the subsequent steps, use instruments when wanted, and full duties with much less hand-holding from the consumer.
That makes GPT-5.5 particularly related for real-world workflows like analysis, coding, writing, evaluation, and productiveness duties. You don’t want to immediate it completely each time. It’s higher at choosing up what you truly need and shifting the duty ahead. So the promise right here is straightforward: not simply higher solutions, however higher execution.
You’ll be able to learn extra about GPT-5.5 right here.
Claude Opus 4.7
Claude Opus 4.7 is Anthropic’s newest frontier mannequin, and in contrast to a minor improve, it seems to be constructed for heavier, extra advanced work. In its launch temporary, Anthropic particularly positions the mannequin for “most troublesome duties” in order to scale back the necessity for supervision. The largest focus is on superior software program engineering, long-running duties, {and professional} workflows the place the mannequin must comply with directions rigorously and keep constant.
Anthropic additionally claims main enhancements in imaginative and prescient, real-world activity dealing with, and reminiscence. Opus 4.7 can apparently course of higher-resolution photos, making it helpful for dense screenshots, diagrams, and document-heavy duties. It is usually stated to carry out higher in areas like finance, authorized, and information work, whereas its improved reminiscence helps throughout lengthy, multi-session tasks.
You’ll be able to learn extra concerning the Claude Opus 4.7 right here.
To offer you a context of their prowess, listed below are the benchmark outcomes of each.
Benchmark Comparability
With a take a look at their benchmark performances, allow us to attempt to perceive what each fashions excel at.
GPT 5.5
GPT-5.5 performs strongly throughout benchmarks that take a look at real-world agentic work. It scores 82.7% on Terminal-Bench 2.0, 73.1% on Knowledgeable-SWE, 84.9% on GDPval, 78.7% on OSWorld-Verified, 55.6% on Toolathlon, and 81.8% on CyberGym. Its reasoning scores are robust too, with 51.7% on FrontierMath Tier 1–3 and 35.4% on FrontierMath Tier 4, whereas GPT-5.5 Professional goes even greater on tougher maths and browser-based duties. So the bigger image is evident: GPT-5.5 is constructed not only for higher solutions, however for coding, instrument use, browser work, maths, and activity execution.
Claude Opus 4.7
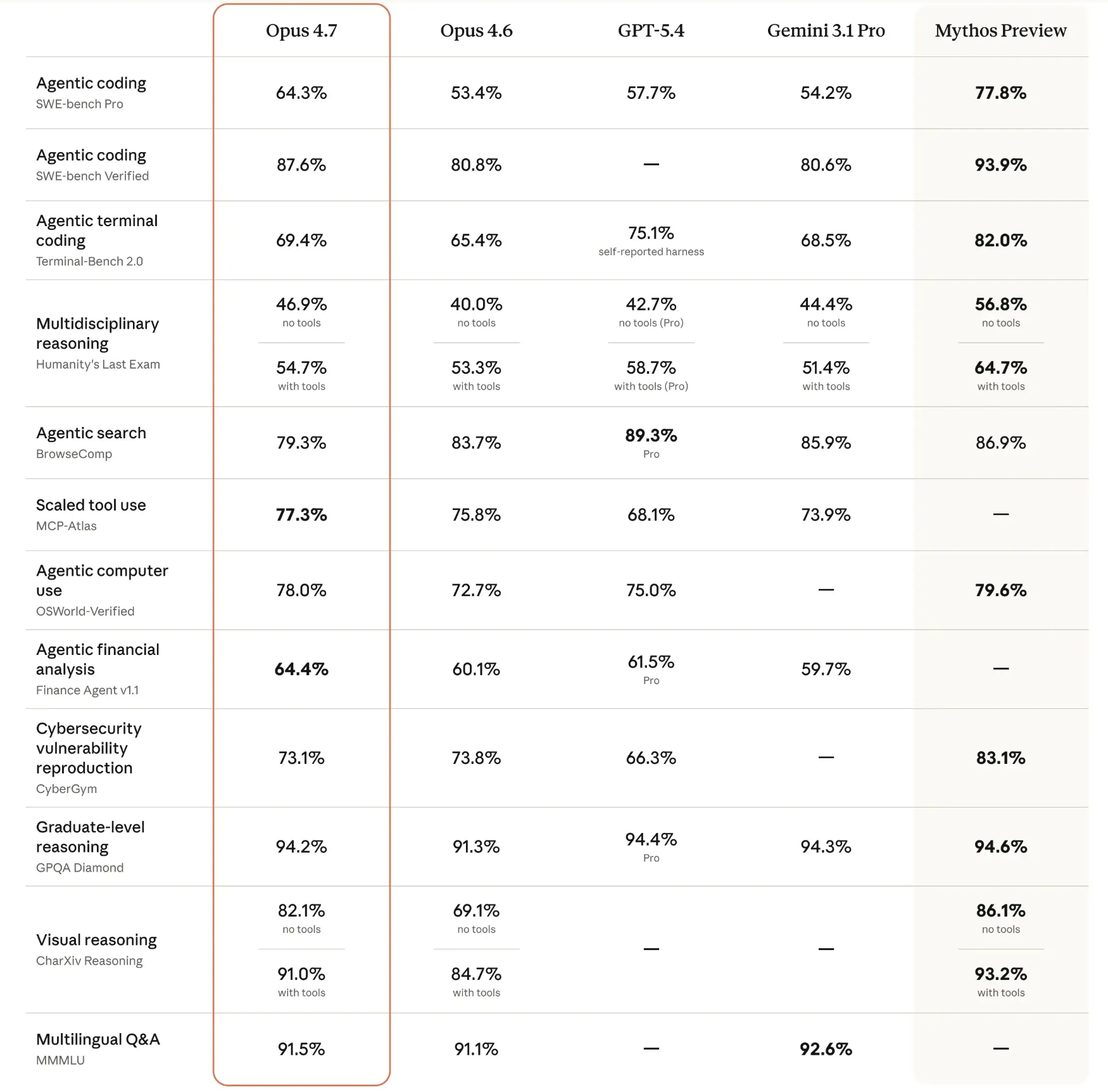
Claude Opus 4.7 additionally performs effectively throughout severe work benchmarks, particularly in coding and reasoning-heavy evaluations. It scores 64.3% on SWE-bench Professional and 87.6% on SWE-bench Verified, displaying robust software program engineering capability. It additionally scores 69.4% on Terminal-Bench 2.0, 94.2% on GPQA Diamond, 91.5% on MMMU, and as much as 91.0% on CharXiv visible reasoning with instruments. These numbers counsel that Opus 4.7 isn’t just a conversational mannequin both. It’s a robust all-rounder for code, imaginative and prescient, search, research-style duties, {and professional} workflows.
How they Evaluate
Taking a look at each fashions collectively, GPT-5.5 appears to have the sting in broader agentic execution, particularly the place browser use, instrument workflows, terminal duties, maths, and autonomous work matter. Opus 4.7, in the meantime, seems particularly robust in software program engineering, visible reasoning, and knowledge-heavy duties. So the distinction shouldn’t be merely “which mannequin is smarter”. GPT-5.5 seems higher suited to end-to-end activity execution, whereas Claude Opus 4.7 seems like a extremely dependable work associate for coding, reasoning, and document-heavy skilled duties.
Primarily based on this, allow us to consider the fashions in real-world exams to search out out the higher mannequin general.
Arms-on: GPT 5.5 vs Opus 4.7
Job 1: Reasoning Job
Immediate:
A startup has ₹50 lakh in funding, 8 months of runway, and three potential income streams: SaaS subscriptions, enterprise consulting, and paid workshops. Construct a 6-month precedence plan and clarify the trade-offs.
GPT 5.5 Output:
Opus 4.7 Output:
Remark:
Okay, so, having gone via the intensive solutions, I’ve noticed that the crux of each outputs is nearly the identical. Each fashions counsel SaaS subscriptions as a long-term purpose, and enterprise gross sales to be on the spot cash. They then proceed to offer a month-wise distribution of all 3 gross sales channels in one of the simplest ways that they’ll consider, which is, once more, just about the identical.
Actually, I like the flowery breakdown and understanding of issues. Although if it have been as much as me, I would go a special route than they counsel (at all times enterprise-first). Nonetheless, if I have been to match the solutions of each, the one by GPT 5.5 is far more elaborate and nuanced than what Opus 4.7 has give you.
The immediately seen enchancment is that GPT 5.5 has given a month-wise breakdown for all the length, full with lists of Focus and Duties for the month. It then proceeds to checklist the professionals and cons of every of the three methods within the trade-offs part. Whereas Opus 4.7 additionally shares data on the identical, it merely doesn’t hit the extent of rationalization that GPT 5.5 reveals right here.
Job 2: Inventive Writing
Immediate:
Write a 600-word article introduction on how AI brokers will change workplace work. Hold the tone sharp, sensible, and non-generic. Keep away from hype. Begin with a well-known quote.
GPT 5.5 Output:
Opus 4.7 Output:
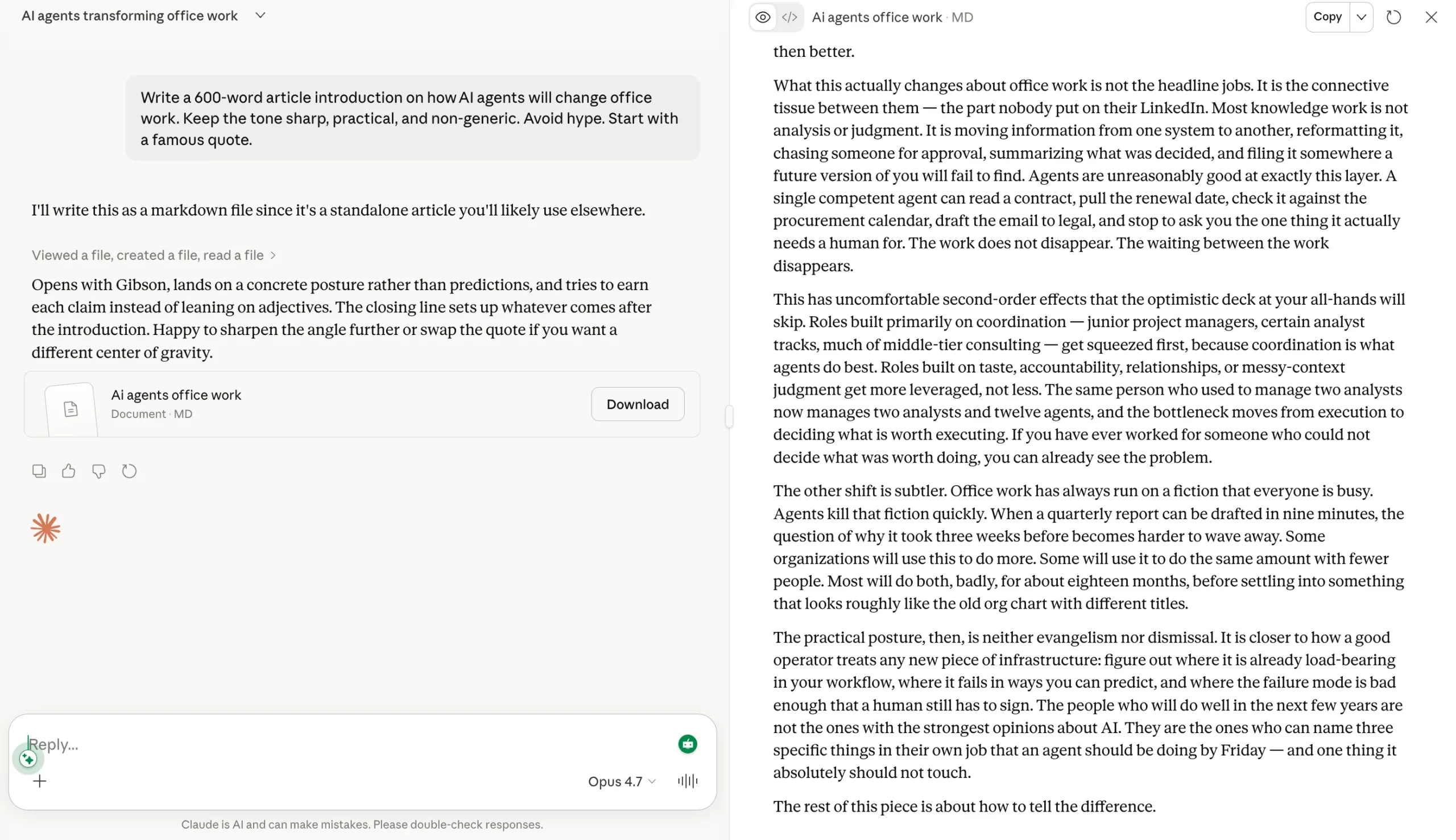
Remark:
What a coincidence we see right here! Each fashions share the very same quote by William Gibson to start with. Goes on to indicate simply how AI is educated throughout materials.
As for the higher writing prowess, Opus 4.7 clearly stands aside with its quirky write-up that resembles far more of a human than what the GPT 5.5 got here up with. And as a author who was utilizing ChatGPT for all of the writing assist until now, I ask – why? Why was I not utilizing Claude earlier than?
Job 3: Coding
Immediate:
Construct a easy Python script that takes a CSV of buyer complaints, classifies them into classes, counts frequency, and exports a abstract report.
GPT 5:5 Output:
Opus 4.7 Output:
Remark:
Each fashions have been capable of churn up a working code for the issue at hand, full with pattern complaints and correct directions to run the code. But, the output by Claude Opus 4.7 feels far more nuanced than what GPT 5.5 has given out. One take a look at the criticism identifiers utilized in each reveals that the Opus 4.7 has considered a a lot bigger number of textual content that will correspond to complaints.
As well as, the Opus 4.7 output additionally incorporates extra parse arguments in order that we will use the enter/ output recordsdata immediately via the terminal, with out making any adjustments within the code. The GPT 5.5 output fully misses that and has used pd.csv as a static.
Curiously, Opus 4.7 was additionally forward with its error dealing with, specifying a correct error as an alternative of the standard code-written errors. e.g. we will see a ValueError throughout the code, which is able to seem each time the consumer inputs the incorrect knowledge sort.
Job 4: Analysis
Immediate:
Create a analysis plan to match India’s EV two-wheeler market with China’s. Embody sources to test, knowledge factors wanted, and potential evaluation angles.
GPT 5.5 Output:
Opus 4.7 Output:
Remark:
Each fashions have give you a fairly intensive checklist of factors to be famous for the analysis. I see that they’ve additionally adopted all of the directions completely and responded with all the information factors we requested for. But, I by some means lean in direction of the output by GPT-5.5, principally due to its reasoning that accompanies every of the factors within the type of “why it issues”, which provides somewhat context to all the checklist, as an alternative of it being only a checklist of factors.
Job 5: Knowledge Evaluation
Immediate:
| Month | Income | CAC | Churn Fee | Conversion Fee |
|---|---|---|---|---|
| January | ₹8,00,000 | ₹2,400 | 4.2% | 3.8% |
| February | ₹9,20,000 | ₹2,650 | 4.5% | 3.6% |
| March | ₹10,10,000 | ₹2,900 | 5.1% | 3.4% |
| April | ₹10,80,000 | ₹3,300 | 5.8% | 3.1% |
| Could | ₹11,20,000 | ₹3,850 | 6.4% | 2.9% |
| June | ₹11,60,000 | ₹4,300 | 7.2% | 2.6% |
Here’s a desk of month-to-month income, CAC, churn, and conversion price. Analyse the enterprise well being, establish dangers, and counsel subsequent actions.
GPT 5.5 Output:
Opus 4.7 Output:
Remark:
As soon as once more, each fashions do the job completely however in a different way, every in their very own type. And as soon as once more, I just like the type of GPT-5.5 far more in presenting the knowledge in the best way that it does. A transparent instance might be seen proper at first. Whereas Opus 4.7 takes you thru a journey throughout the output, GPT-5.5 tells you immediately that the CAC is rising method sooner than income. Since this is among the first issues even a human will discover by wanting on the desk, I consider that could be a job higher performed than any AI output.
Job 6: Imaginative and prescient Take a look at
Immediate:
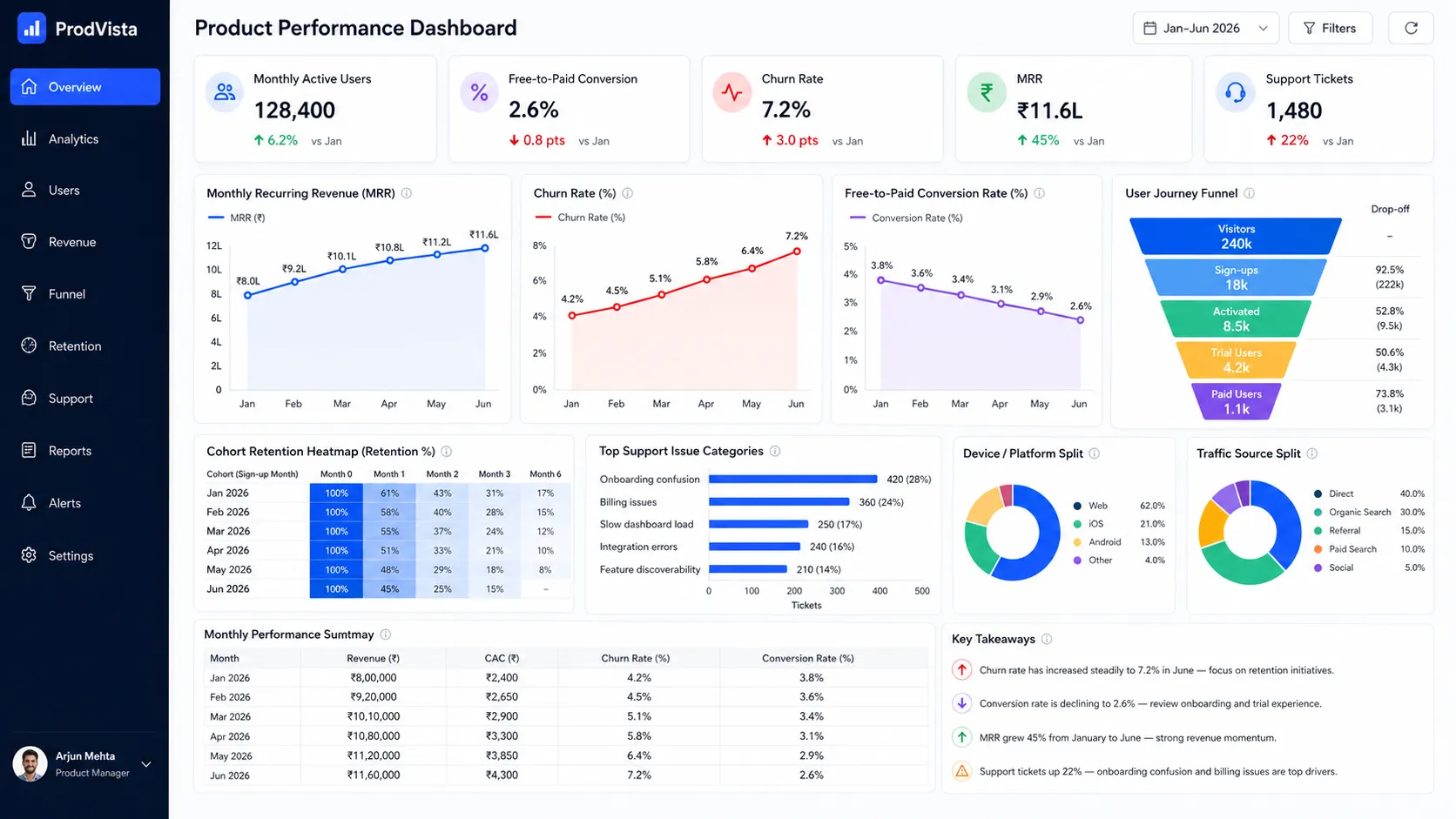
Analyse this product dashboard screenshot. Determine the primary developments, potential issues, and what motion the group ought to take subsequent.
GPT 5.5 Output:
Opus 4.7 Output:
Remark:
Each fashions current a terrific output right here, full with the subsequent steps to be carried out as an answer. As soon as extra, GPT-5.5 merely takes the extra brownie factors because of its presentation, which is full with tables, lists, and direct, easy-to-follow pointers for fast understanding.
Job 7: Agentic Duties
Immediate:
I wish to launch a distinct segment AI e-newsletter in 30 days. Create a whole execution plan with every day duties, instruments required, content material workflow, and monetisation path.
GPT 5:5 Output:
Opus 4.7 Output:
Remark:
Outputs from each GPT-5.5 and Opus 4.7 are nearly comparable, mentioning an in depth, day-wise breakup of what’s to be performed and the way. Each have listed essential instruments which can be certain to assist alongside the method. I particularly appreciated the phase-wise break-ups in every case, steadily constructing in direction of monetisation. One factor that stood out was that whereas Opus 4.7 lists day 1 for brainstorming round concepts, GPT-5.5 helped a bit extra by truly presenting a wide range of concepts proper from the beginning, most of which sound extraordinarily legitimate and helpful. In order that’s a giant bounce, proper from the beginning. Aside from that, you possibly can comply with both output for a profitable, area of interest AI e-newsletter.
Also learn: Prime 20 AI Instruments for Work: 10X Your Output
Conclusion
I can be mendacity if I stated I choose any one among these fashions over the opposite. Within the GPT-5.5 vs Opus 4.7 battle, the one certainty is that the fashions will provide help to much more together with your on a regular basis work than AI ever did within the historical past of humankind. Their outputs, throughout all use instances, are a obtrusive testimony of how far AI has come.
As for which one is healthier, our exams performed above counsel that each fashions have their very own areas of experience. Whereas Claude Opus 4.7 is method higher in coding and writing, GPT-5.5 takes the lead in many of the reasoning duties and on a regular basis workflows. Also, I personally choose it over Claude for some easy and refined causes – it’s extra upfront and direct with the core question, its outputs are far more presentable and simpler to know, and better of all, it truly appears like a human counterpart, as that is precisely how pure conversations movement. You ask, and the particular person in entrance of you solutions, particular to the question. A human doesn’t offer you an elaborate rationalization of issues simply because.
And that’s, or slightly it must be, the end-goal with AI. A really good AI would perceive precisely what the consumer needs from their question, after which reply appropriately. If it provides you a solution from the cumulative information of the subject and you need to hunt for the answer inside it, it beats the aim of getting an AI within the first place.
As for which one to make use of when, right here is my last advice:
| Take a look at Class | Higher Performing Mannequin |
|---|---|
| Reasoning Duties | GPT-5.5 |
| Inventive Writing | Opus 4.7 |
| Coding | Opus 4.7 |
| Analysis | GPT-5.5 (barely higher) |
| Knowledge Evaluation | GPT-5.5 / Opus 4.7 |
| Imaginative and prescient | GPT-5.5 / Opus 4.7 |
| Agentic Duties | GPT-5.5 |
| General | GPT-5.5 is far more direct, presentable and simpler to know |
Which one do you like utilizing? Let me know within the feedback!
Login to proceed studying and luxuriate in expert-curated content material.






{kind=link}