Introduction
OpenAI launched GPT-4o mini yesterday (18th June 2024), taking the world by storm. There are a number of causes for this. OpenAI has historically targeted on giant language fashions (LLMs), which take lots of computing energy and have important prices related to utilizing them. Nevertheless, with this launch, they’re formally venturing into small language fashions (SLMs) territory and competing in opposition to fashions like Llama 3, Gemma 2, and Mistral. Whereas many official benchmark outcomes and efficiency comparisons have been launched, I considered placing this mannequin to the take a look at in opposition to its two predecessors, GPT-3.5 Turbo, and their latest flagship mannequin, GPT-4o, in a collection of various duties. So, let’s dive in and see extra particulars about GPT-4o mini and its efficiency.
Overview
- OpenAI launches GPT-4o mini, a small language mannequin (SLM), competing with fashions like Llama 3 and Mistral.
- GPT-4o mini presents low price, low latency, and near-real-time responses with a big 128K token context window.
- The mannequin helps textual content and picture inputs with future plans for audio and video help.
- GPT-4o mini excels in reasoning, math, and coding benchmarks, outperforming predecessors and rivals.
- It’s out there in OpenAI’s API providers at aggressive pricing, making superior AI extra accessible.
Unboxing GPT-4o mini and its options
This part will attempt to perceive all the main points about OpenAI’s new GPT-4o mini mannequin. Based mostly on their current announcement, this mannequin has been launched, specializing in making entry to clever fashions extra reasonably priced. It has low price (extra on this shortly) and latency. It allows customers to construct Generative AI functions quicker, processing giant volumes of textual content due to its giant context window, giving near-real-time responses, and parallelizing a number of API calls.
GPT-4o mini, identical to its predecessor, GPT-4o, is a multimodal mannequin and has help for textual content, photos, audio, and video. Proper now, it solely helps textual content and picture, sadly, with the opposite enter choices to be launched someday sooner or later. This mannequin has been educated on information upto October 2023 and has an enormous enter context window of 128K tokens and an output response token restrict of 16K per request. This mannequin shares the identical tokenizer as GPT-4o and therefore has improved responses for prompts in non-English languages.
GPT-4o mini efficiency comparisons
OpenAI has considerably examined GPT-4o mini’s efficiency throughout a wide range of normal benchmark datasets specializing in various duties and evaluating it with a number of different giant language fashions (LLMs), together with Gemini, Claude, and its predecessors, GPT-3.5 and GPT-4o.
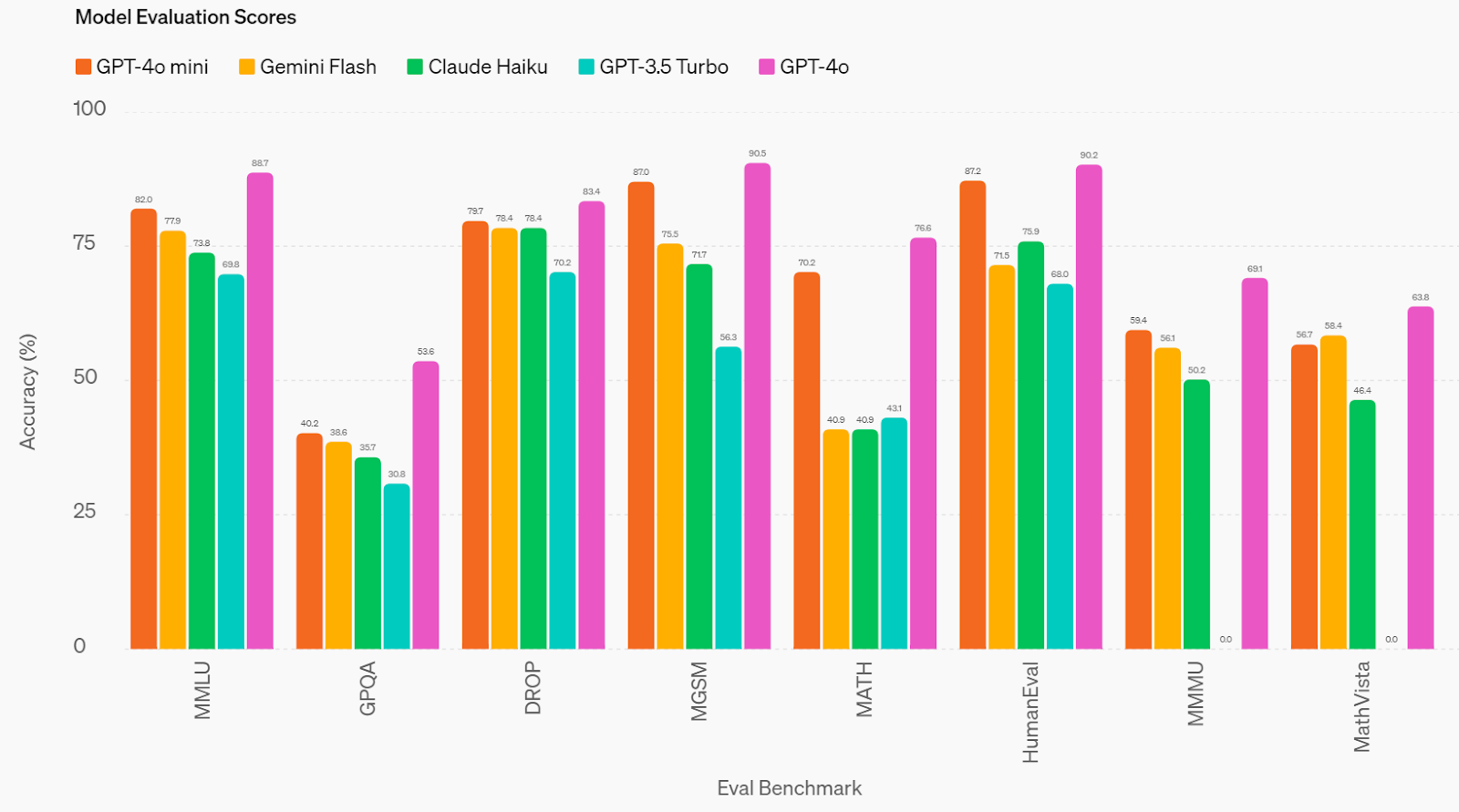
OpenAI claims that GPT-4o mini performs considerably higher than GPT-3.5 Turbo and different fashions in textual intelligence, multimodal reasoning, math, and coding proficiency benchmarks. As you may see within the above-mentioned visualization, GPT-4o mini has been evaluated throughout a number of key benchmarks, together with:
- Reasoning: GPT-4o mini is best at reasoning duties involving each textual content and imaginative and prescient, scoring 82.0% on the Huge Multitask Language Understanding (MMLU) dataset, which is textual intelligence and reasoning benchmark, as in comparison with 77.9% for Gemini Flash and 73.8% for Claude Haiku.
- Mathematical Proficiency: On the Multilingual Grade College Math Benchmark (MGSM), which measures math reasoning utilizing grade-school math issues, GPT-4o mini scored 87.0%, in comparison with 75.5% for Gemini Flash and 71.7% for Claude Haiku.
- Coding Proficiency: GPT-4o mini scored 87.2% on HumanEval, which measures coding proficiency by taking a look at purposeful correctness for synthesizing packages from docstrings, in comparison with 71.5% for Gemini Flash and 75.9% for Claude Haiku.
- Multimodal reasoning: GPT-4o mini additionally reveals sturdy efficiency on the Huge Multi-discipline Multimodal Understanding (MMMU) dataset, a multimodal reasoning benchmark, scoring 59.4% in comparison with 56.1% for Gemini Flash and 50.2% for Claude Haiku.
We even have detailed evaluation and comparisons accomplished by Synthetic Evaluation, an impartial group that gives benchmarking and associated data for varied LLMs and SLMs. The next visible clearly reveals how GPT-4o mini focuses on offering high quality responses at blazing-fast speeds as in comparison with most different fashions.
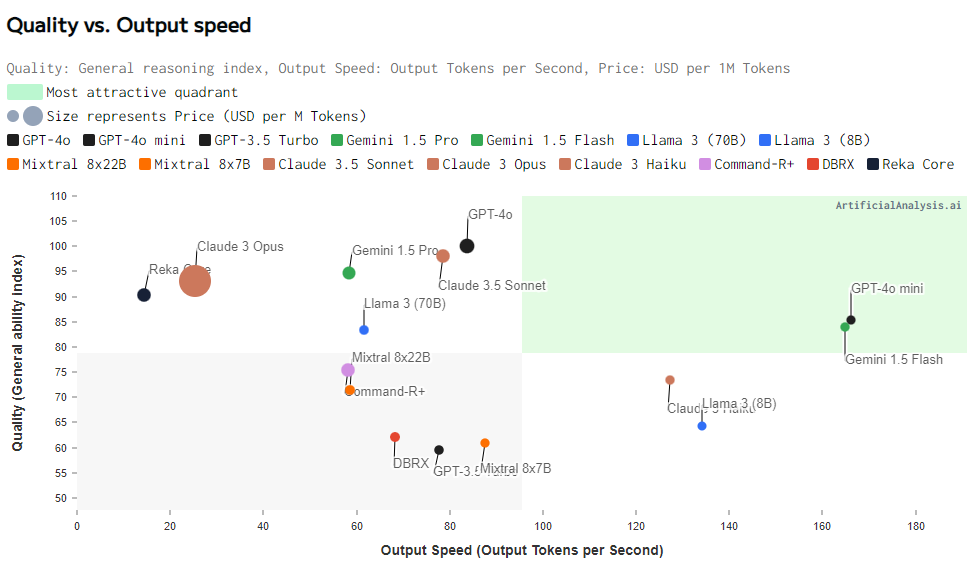
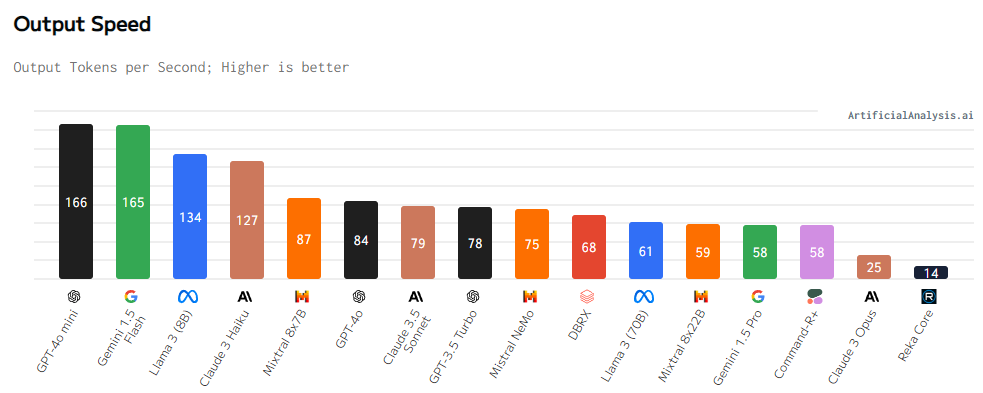
In addition to the efficiency of the mannequin by way of high quality of outcomes, there are a few components which we often contemplate when selecting an LLM or SLM, this consists of the response pace and value. Contemplating these components, we get a wide range of comparisons, together with the mannequin’s output pace, which mainly focuses on the output tokens per second obtained whereas the mannequin is producing tokens (ie, after the primary chunk has been obtained from the API). These numbers are based mostly on the median pace throughout all suppliers, and as claimed by their observations, GPT-4o-mini appears to have the best output pace, which is fairly fascinating, as seen within the following visible
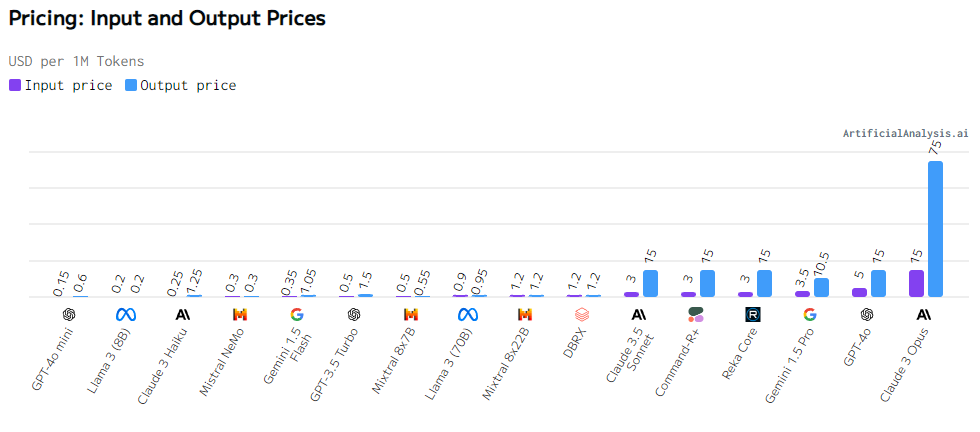
We additionally get an in depth comparability from Synthetic Evaluation on the price of utilizing GPT-4o mini vs different widespread fashions. Right here, the pricing is proven by way of each enter prompts and output responses in USD per 1M (million) tokens. GPT-4o mini is sort of low cost, contemplating you do not want to fret about internet hosting it, organising your personal GPU infrastructure, and sustaining it!
OpenAI additionally mentions that GPT-4o mini demonstrates sturdy efficiency in perform and gear calling, which suggests you will get higher efficiency when utilizing this mannequin to construct AI Brokers and sophisticated Agentic AI programs that may fetch dwell information from the net, purpose, observe, and take actions with exterior programs and instruments. GPT-4o mini additionally has improved long-context efficiency in comparison with GPT-3.5 Turbo and in addition performs nicely in duties like extracting structured information from receipts or producing high-quality e-mail responses when supplied with the total dialog historical past.
Also Learn: Right here’s How You Can Use GPT 4o API for Imaginative and prescient, Textual content, Picture & Extra.
GPT-4o mini availability and pricing comparisons
OpenAI has made GPT-4o mini out there as a textual content and imaginative and prescient mannequin instantly within the Assistant API, Chat Completion API, and the Batch API. You solely must pay 15 cents per 1M (million) enter immediate tokens and 60 cents per 1M output response tokens. For ease of understanding, that’s roughly the equal of a 2500-page e book!
It is usually the most affordable mannequin from OpenAI but compared to its earlier fashions, as seen within the following desk, the place we’ve condensed all of the pricing data
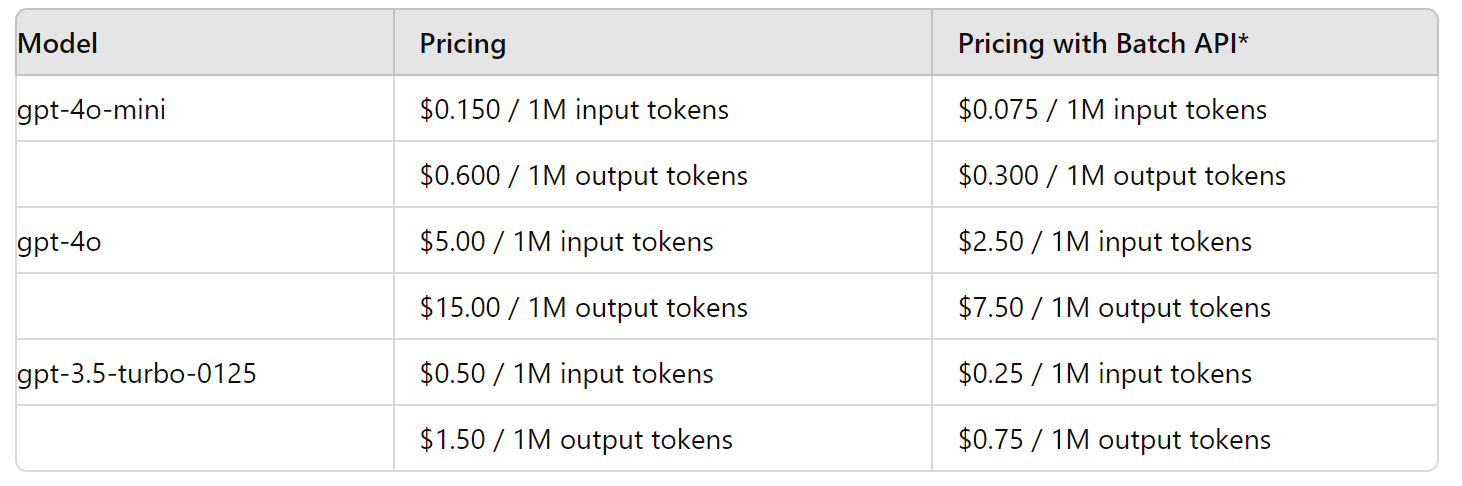
In ChatGPT, Free, plus, and Staff customers will have the ability to entry GPT-4o mini very quickly, throughout this week (the third week of July 2024).
Placing GPT-4o mini to the take a look at
We are going to now put GPT-4o mini to the take a look at and evaluate it with its two predecessors, GPT-4o and GPT-3.5 Turbo in varied widespread duties based mostly on real-world issues. The important thing duties we’ll we specializing in embrace the next:
- Activity 1: Zero-shot Classification
- Activity 2: Few-shot Classification
- Activity 3: Coding Duties – Python
- Activity 4: Coding Duties – SQL
- Activity 5: Data Extraction
- Activity 6: Closed-Area Query Answering
- Activity 7: Open-Area Query Answering
- Activity 8: Doc Summarization
- Activity 9: Transformation
- Activity 10: Translation
Please word that the intent of this train is to not run any fashions on benchmark datasets however to take an instance in every downside and see how nicely GPT-4o mini responds to it in comparison with the opposite two OpenAI fashions. Let the present start!
Set up Dependencies
We begin by putting in the required dependencies, which is mainly the OpenAI library to entry its APIs
!pip set up openaiEnter OpenAI API Key
We enter our OpenAI key utilizing the getpass() perform so we don’t by accident expose our key within the code.
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')Setup API Key
Subsequent, we setup our API key to make use of with the openai library
import openai
from IPython.show import HTML, Markdown, show
openai.api_key = openai_keyCreate ChatGPT Completion Entry Perform
This perform will use the Chat Completion API to entry ChatGPT for us and return responses based mostly on the mannequin we wish to use together with GPT-3.5 Turbo, GPT-4o, and GPT-4o mini.
def get_completion(immediate, mannequin="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.chat.completions.create(
mannequin=mannequin,
messages=messages,
temperature=0.0, # diploma of randomness of the mannequin's output
)
return response.decisions[0].message.content materialLet’s check out the ChatGPT API!
We are able to shortly take a look at the above perform to see if our code can entry OpenAI’s servers and use their fashions.
response = get_completion(immediate="Clarify Generative AI in 2 bullet factors",
mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT

Appears to be working as anticipated; we are able to now begin with our experiments!
Also Learn: GPT-4o vs Gemini: Evaluating Two Highly effective Multimodal AI Fashions
Activity 1: Zero-shot Classification
This job exams an LLM’s textual content classification capabilities by prompting it to categorise a textual content with out offering examples. Right here, we’ll do a zero-shot sentiment evaluation on some buyer product opinions. We’ve three buyer opinions as follows:
opinions = [
f"""
Just received the Bluetooth speaker I ordered for beach outings, and it's
fantastic. The sound quality is impressively clear with just the right amount of
bass. It's also waterproof, which tested true during a recent splashing
incident. Though it's compact, the volume can really fill the space.
The price was a bargain for such high-quality sound.
Shipping was also on point, arriving two days early in secure packaging.
""",
f"""
Needed a new kitchen blender, but this model has been a nightmare.
It's supposed to handle various foods, but it struggles with anything tougher
than cooked vegetables. It's also incredibly noisy, and the 'easy-clean' feature
is a joke; food gets stuck under the blades constantly.
I thought the brand meant quality, but this product has proven me wrong.
Plus, it arrived three days late. Definitely not worth the expense.
""",
f"""
I tried to like this book and while the plot was really good, the print quality
was so not good
"""
]We now create a immediate to do zero-shot textual content classification and run it in opposition to the three opinions utilizing every of the three OpenAI fashions individually.
responses = {
'gpt-3.5-turbo' : [],
'gpt-4o' : [],
'gpt-4o-mini' : []
}
for assessment in opinions:
immediate = f"""
Act as a product assessment analyst.
Given the next assessment,
Show the general sentiment for the assessment
as solely one of many following:
Optimistic, Detrimental OR Impartial
```{assessment}```
"""
response = get_completion(immediate, mannequin="gpt-3.5-turbo")
responses['gpt-3.5-turbo'].append(response)
response = get_completion(immediate, mannequin="gpt-4o")
responses['gpt-4o'].append(response)
response = get_completion(immediate, mannequin="gpt-4o-mini")
responses['gpt-4o-mini'].append(response)# Show the output
import pandas as pd
pd.set_option('show.max_colwidth', None)
pd.DataFrame(responses)OUTPUT

The outcomes are principally constant throughout the fashions, besides GPT-3.5 Turbo fails simply to return the sentiment for the 2nd instance.
Activity 2: Few-shot Classification
This job exams an LLM’s textual content classification capabilities by prompting it to categorise a textual content by offering examples of inputs and outputs. Right here, we’ll classify the identical buyer opinions as these given within the earlier instance utilizing few-shot prompting.
responses = {
'gpt-3.5-turbo' : [],
'gpt-4o' : [],
'gpt-4o-mini' : []
}
for assessment in opinions:
immediate = f"""
Act as a product assessment analyst.
Given the next assessment,
Show solely the general sentiment for the assessment:
Attempt to classify it through the use of the next examples as a reference:
Assessment: Simply obtained the Laptop computer I ordered for work, and it is wonderful.
Sentiment: 😊
Assessment: Wanted a brand new mechanical keyboard, however this mannequin has been
completely disappointing.
Sentiment: 😡
Assessment: ```{assessment}```
"""
response = get_completion(immediate, mannequin="gpt-3.5-turbo")
responses['gpt-3.5-turbo'].append(response)
response = get_completion(immediate, mannequin="gpt-4o")
responses['gpt-4o'].append(response)
response = get_completion(immediate, mannequin="gpt-4o-mini")
responses['gpt-4o-mini'].append(response)
# Show the output
pd.DataFrame(responses)OUTPUT

We see very comparable outcomes throughout fashions, though for the third assessment is which is definitely form of combined, we get fascinating emoji outputs from the fashions, GPT-3.5 Turbo and GPT-4o give us a confused face emoji (😕), and GPT-4o mini give us a impartial or mildly disenchanted face emoji (😐)
Activity 3: Coding Duties – Python
This job exams an LLM’s capabilities for producing Python code based mostly on sure prompts. Right here we attempt to concentrate on a key job of scaling your information earlier than making use of sure machine studying fashions.
immediate = f"""
Act as an knowledgeable in producing python code
Your job is to generate python code
to clarify easy methods to scale information for a ML downside.
Deal with simply scaling and nothing else.
Maintain under consideration key operations we must always do on the info
to forestall information leakage earlier than scaling.
Maintain the code and reply concise.
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT

Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT

Total, all 3 fashions do fairly nicely, though personally, I like GPT-4o mini’s rationalization higher, particularly level 3, the place we speak about utilizing the fitted scaler to remodel the take a look at information, which is defined higher than the response from GPT-4o. We additionally see that the response types of each GPT-4o and GPT-4o mini are fairly comparable!
Activity 4:Coding Duties – SQL
This job exams an LLM’s capabilities for producing SQL code based mostly on sure prompts. Right here we attempt to concentrate on a barely extra advanced question involving a number of database tables.
immediate = f"""
Act as an knowledgeable in producing SQL code.
Perceive the next schema of the database tables rigorously:
Desk departments, columns = [DepartmentId, DepartmentName]
Desk workers, columns = [EmployeeId, EmployeeName, DepartmentId]
Desk salaries, columns = [EmployeeId, Salary]
Create a MySQL question for the worker with max wage within the 'IT' Division.
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT

Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT
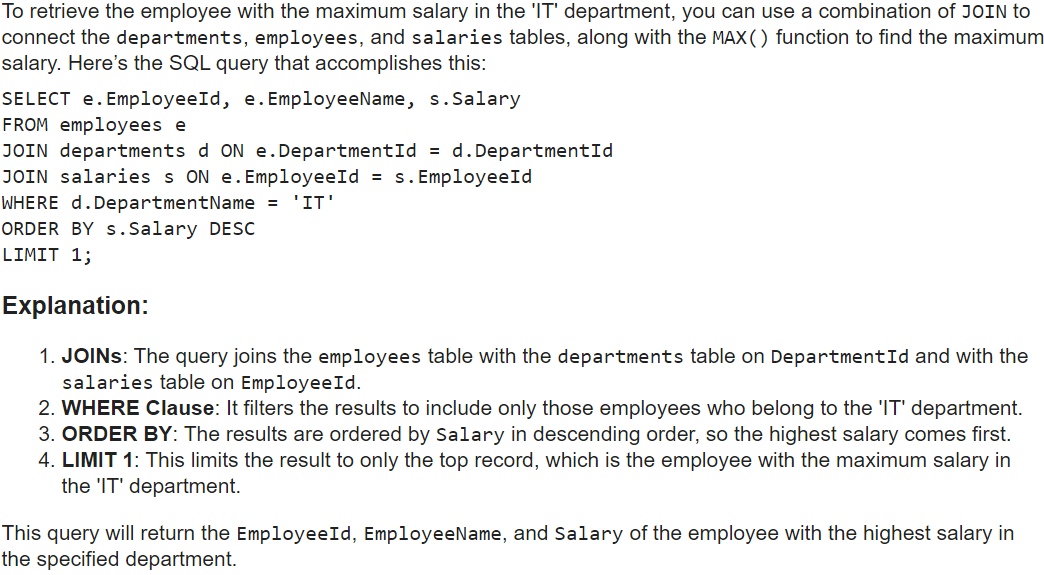
Total, all three fashions do fairly nicely. We additionally see that the response types of each GPT-4o and GPT-4o mini are fairly comparable. Each give the identical question and a few detailed rationalization of what’s taking place within the question. GPT-4o offers probably the most detailed rationalization of the question step-by-step.
This job exams an LLM’s capabilities for extracting and analyzing key entities from paperwork. Right here we’ll extract and develop on essential entities in a medical word.
clinical_note = """
60-year-old man in NAD with a h/o CAD, DM2, bronchial asthma, pharyngitis, SBP,
and HTN on altace for 8 years awoke from sleep round 1:00 am this morning
with a sore throat and swelling of the tongue.
He got here instantly to the ED as a result of he was having problem swallowing and
some hassle respiration on account of obstruction brought on by the swelling.
He didn't have any related SOB, chest ache, itching, or nausea.
He has not observed any rashes.
He says that he appears like it's swollen down in his esophagus as nicely.
He doesn't recall vomiting however says he may need retched a bit.
Within the ED he was given 25mg benadryl IV, 125 mg solumedrol IV,
and pepcid 20 mg IV.
Household historical past of CHF and esophageal most cancers (father).
"""immediate = f"""
Act as an knowledgeable in analyzing and understanding medical physician notes in healthcare.
Extract all signs solely from the medical word beneath in triple backticks.
Differentiate between signs which might be current vs. absent.
Give me the likelihood (excessive/ medium/ low) of how certain you might be in regards to the outcome.
Add a word on the chances and why you assume so.
Output as a markdown desk with the next columns,
all signs needs to be expanded and no acronyms until you do not know:
Signs | Current/Denies | Chance.
Also develop the acronyms within the word together with signs and different medical phrases.
Don't omit any acronym associated to healthcare.
Output that additionally as a separate appendix desk in Markdown with the next columns,
Acronym | Expanded Time period
Medical Notice:
```{clinical_note}```
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT
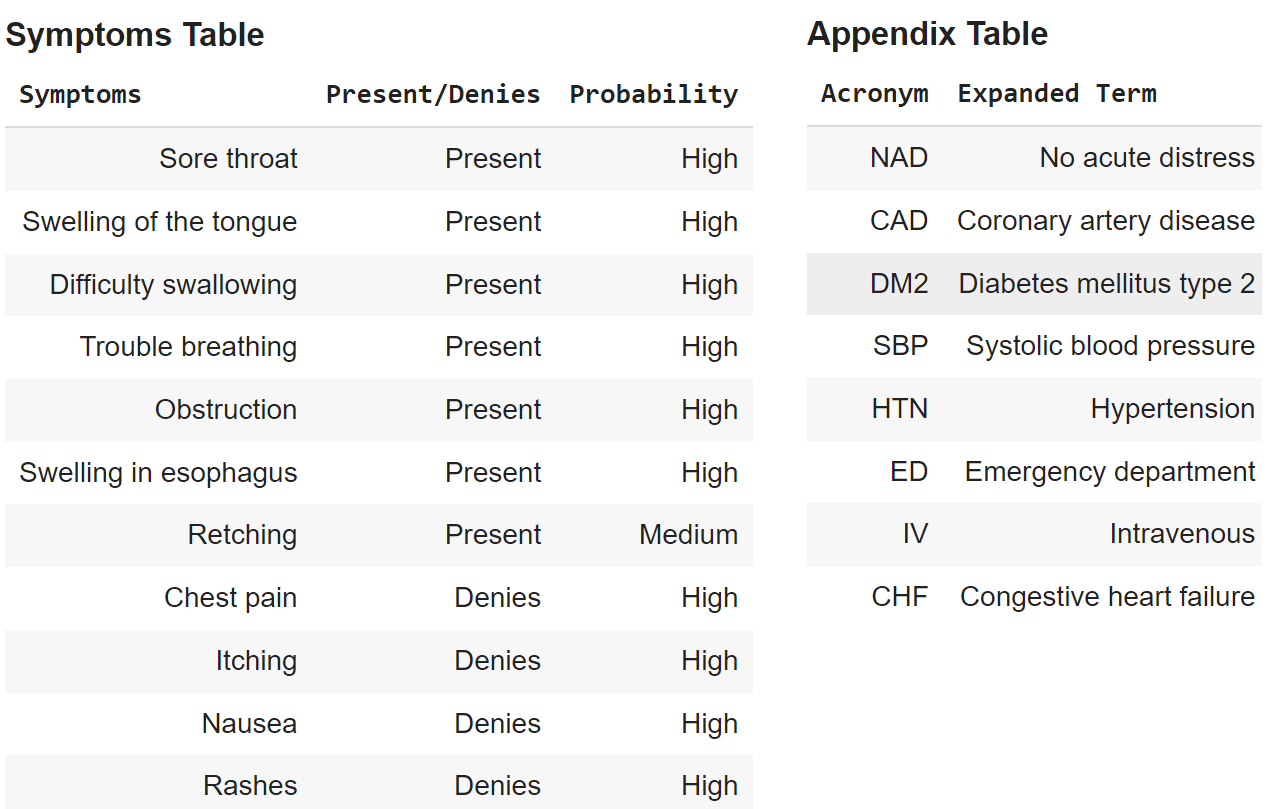
We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT
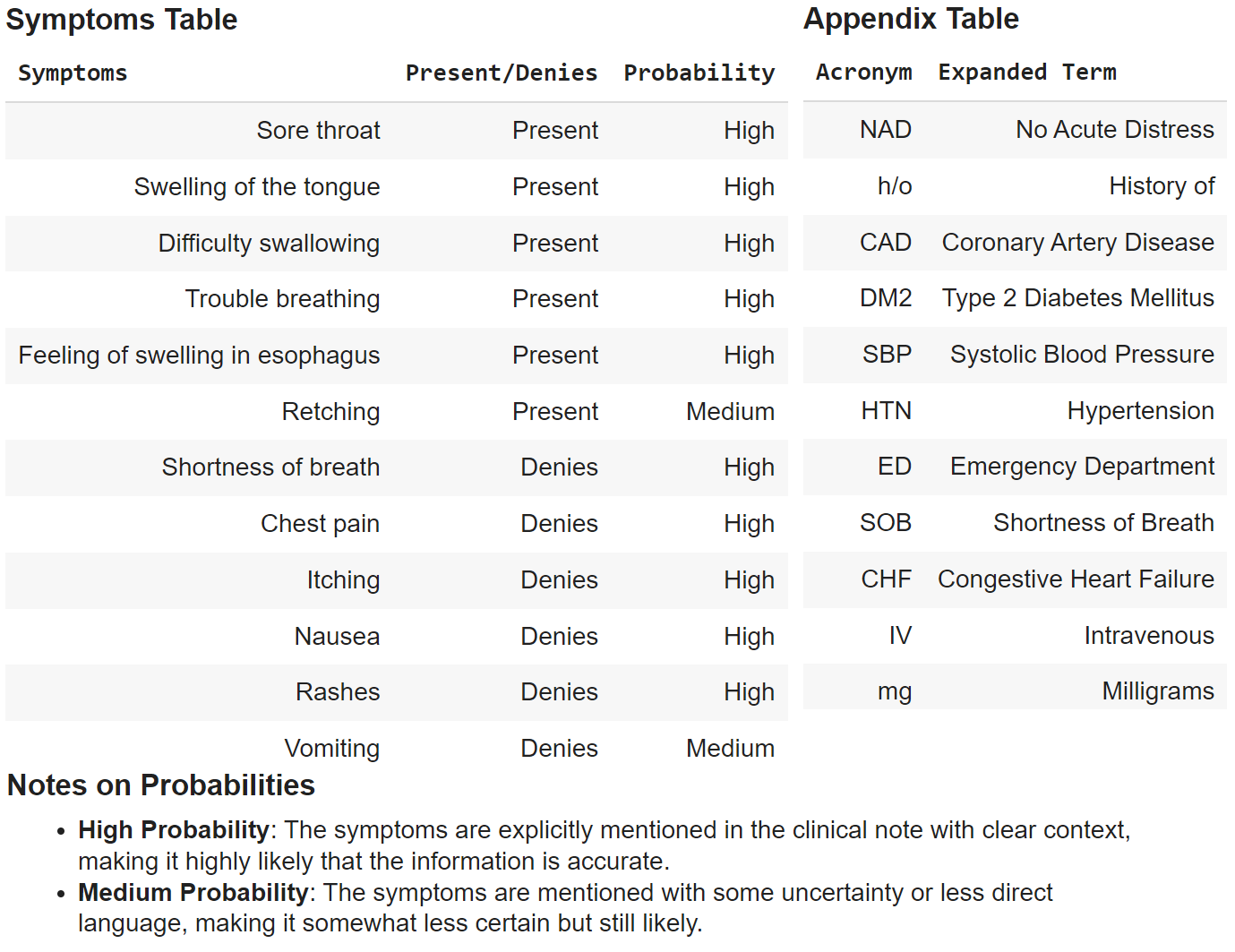
Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT
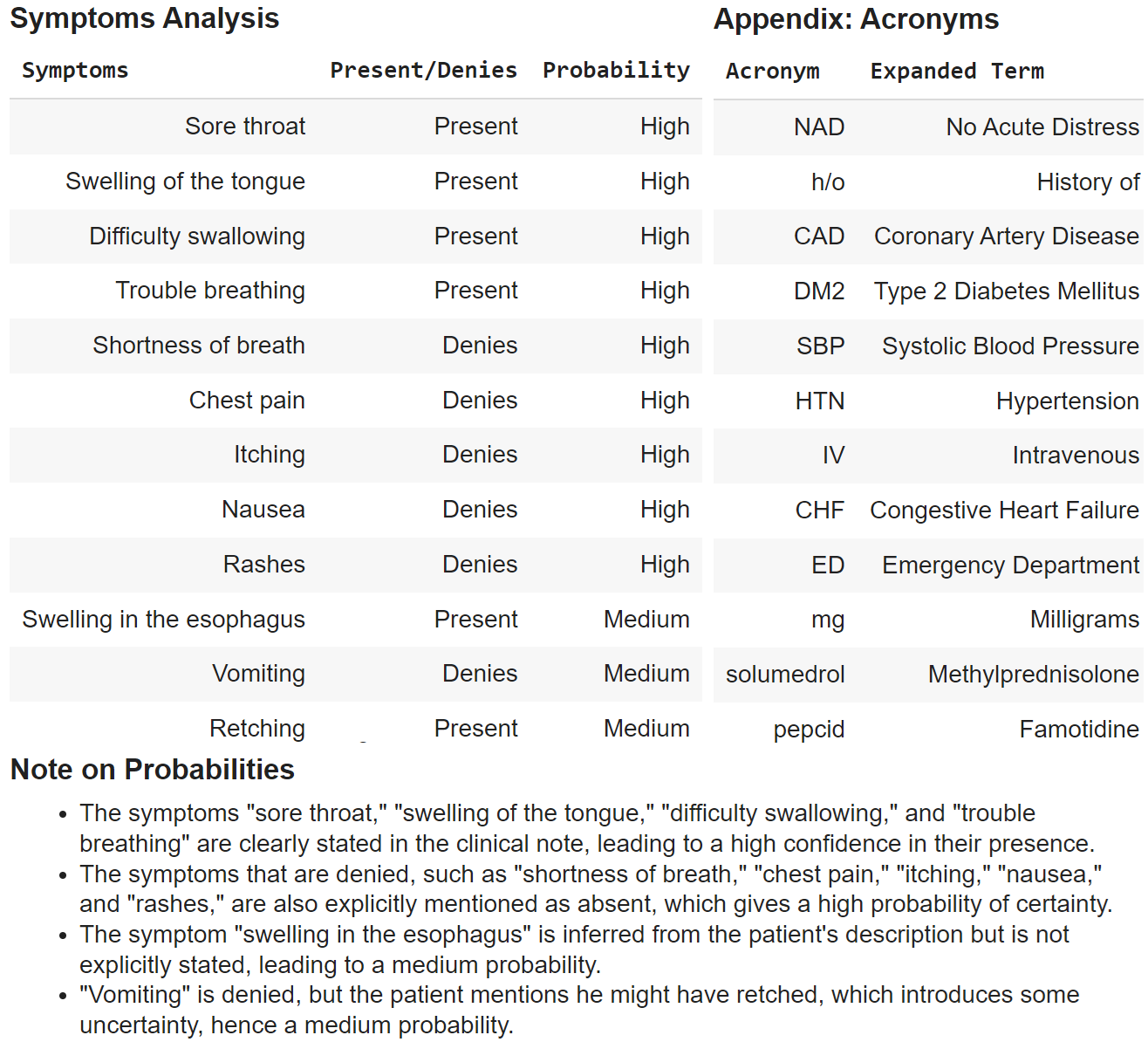
Total, GPT-3.5 Turbo fails to comply with all of the directions and doesn’t give reasoning on the likelihood scoring, which is adopted faithfully by each GPT-4o and GPT-4o mini, which give solutions in an analogous type. GPT-4o most likely is ready to give one of the best responses though GPT-4o mini comes fairly shut and truly offers extra detailed reasoning on the likelihood scoring. Each the fashions carry out neck to neck, the one shortcoming right here is that GPT-4o mini didn’t put SOB as shortness of breath within the 2nd desk though it did develop it within the signs desk. Apparently, the final two rows of the appendix desk of GPT-4o mini are frequent names of medication the place it has expanded the model identify to the precise drug ingredient names!
Also Learn: The Omniscient GPT-4o + ChatGPT is HERE!
Activity 6: Closed-Area Query Answering
Query Answering (QA) is a pure language processing job that generates the specified reply for the given query. Query Answering will be open-domain QA or closed-domain QA, relying on whether or not the LLM is supplied with the related context or not.
In closed-domain QA, a query together with related context is given. Right here, the context is nothing however the related textual content, which ideally ought to have the reply, identical to a RAG workflow.
report = """
Three quarters (77%) of the inhabitants noticed a rise of their common outgoings over the previous 12 months,
in line with findings from our current shopper survey. In distinction, simply over half (54%) of respondents
had a rise of their wage, which means that the burden of prices outweighing earnings stays for
most. In whole, throughout the two,500 individuals surveyed, the rise in outgoings was 18%, 3 times increased
than the 6% improve in earnings.
Regardless of this, the findings of our survey counsel we've reached a plateau. Taking a look at financial savings,
for instance, the share of people that count on to make common financial savings this 12 months is simply over 70%,
broadly just like final 12 months. Over half of these saving plan to make use of a few of the funds for residential
property. A 3rd are saving for a deposit, and an extra 20% for an funding property or second dwelling.
However for some, their plans are being pushed again. 9% of respondents acknowledged they'd deliberate to buy
a brand new dwelling this 12 months however have now modified their thoughts. Whereas for a lot of the deposit could also be a difficulty,
the opposite driving issue stays the price of the mortgage, which has been steadily rising the final
few years. For people who at the moment personal a property, the survey confirmed that within the final 12 months,
the typical mortgage fee has elevated from £668.51 to £748.94, or 12%."""
query = """
How a lot has the typical mortage fee elevated within the final 12 months?
"""
immediate = f"""
Utilizing the next context data beneath please reply the next query
to one of the best of your means
Context:
{report}
Query:
{query}
Reply:
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT
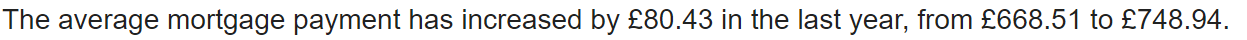
Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT
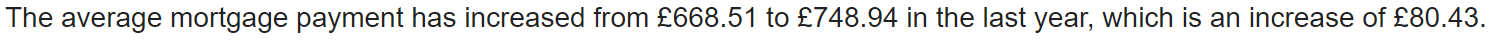
Fairly normal solutions throughout all three fashions right here; nothing considerably completely different.
Activity 7: Open-Area Query Answering
Query Answering (QA) is a pure language processing job that generates the specified reply for the given query.
Within the case of open-domain QA, solely the query is requested with out offering any context or data. Right here, the LLM solutions the query utilizing the data gained from giant volumes of textual content information throughout its coaching. That is mainly Zero-Shot QA. That is the place the mannequin’s data cutoff when it was educated, turns into essential to reply questions, particularly on current occasions!
immediate = f"""
Please reply the next query to one of the best of your means
Query:
What's LangChain?
Reply:
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT

Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT

Now, LangChain is a reasonably new framework for constructing Generative AI functions, and that’s the reason GPT-3.5 Turbo offers a completely improper reply, as the info it was educated on by no means had any mentions of this LangChain library. Whereas it may be known as a hallucination, factually, it isn’t as a result of lengthy again, there really was once a blockchain framework known as LangChain earlier than Net 3.0, NFTs, and Blockchain went into slumber mode. GPT-4o and GPT-4o mini give the suitable reply right here, with GPT-4o mini giving a barely detailed reply, however this may be managed by placing constraints on the output format for even GPT-4o.
Activity 8: Doc Summarization
Doc summarization is a pure language processing job that entails making a concise abstract of the given textual content whereas nonetheless capturing all of the essential data.
doc = """
Coronaviruses are a big household of viruses which can trigger sickness in animals or people.
In people, a number of coronaviruses are identified to trigger respiratory infections starting from the
frequent chilly to extra extreme illnesses corresponding to Center East Respiratory Syndrome (MERS) and Extreme Acute Respiratory Syndrome (SARS).
Probably the most just lately found coronavirus causes coronavirus illness COVID-19.
COVID-19 is the infectious illness brought on by probably the most just lately found coronavirus.
This new virus and illness have been unknown earlier than the outbreak started in Wuhan, China, in December 2019.
COVID-19 is now a pandemic affecting many nations globally.
The most typical signs of COVID-19 are fever, dry cough, and tiredness.
Different signs which might be much less frequent and should have an effect on some sufferers embrace aches
and pains, nasal congestion, headache, conjunctivitis, sore throat, diarrhea,
lack of style or scent or a rash on pores and skin or discoloration of fingers or toes.
These signs are often gentle and start steadily.
Some individuals develop into contaminated however solely have very gentle signs.
Most individuals (about 80%) get well from the illness without having hospital therapy.
Round 1 out of each 5 individuals who will get COVID-19 turns into significantly in poor health and develops problem respiration.
Older individuals, and people with underlying medical issues like hypertension, coronary heart and lung issues,
diabetes, or most cancers, are at increased danger of creating severe sickness.
Nevertheless, anybody can catch COVID-19 and develop into significantly in poor health.
Individuals of all ages who expertise fever and/or cough related to problem respiration/shortness of breath,
chest ache/stress, or lack of speech or motion ought to search medical consideration instantly.
If attainable, it is strongly recommended to name the well being care supplier or facility first,
so the affected person will be directed to the suitable clinic.
Individuals can catch COVID-19 from others who've the virus.
The illness spreads primarily from individual to individual by small droplets from the nostril or mouth,
that are expelled when an individual with COVID-19 coughs, sneezes, or speaks.
These droplets are comparatively heavy, don't journey far and shortly sink to the bottom.
Individuals can catch COVID-19 in the event that they breathe in these droplets from an individual contaminated with the virus.
That is why you will need to keep at the least 1 meter) away from others.
These droplets can land on objects and surfaces across the individual corresponding to tables, doorknobs and handrails.
Individuals can develop into contaminated by touching these objects or surfaces, then touching their eyes, nostril or mouth.
That is why you will need to wash your palms commonly with cleaning soap and water or clear with alcohol-based hand rub.
Working towards hand and respiratory hygiene is essential at ALL occasions and is the easiest way to guard others and your self.
When attainable keep at the least a 1 meter distance between your self and others.
That is particularly essential in case you are standing by somebody who's coughing or sneezing.
Since some contaminated individuals might not but be exhibiting signs or their signs could also be gentle,
sustaining a bodily distance with everyone seems to be a good suggestion in case you are in an space the place COVID-19 is circulating."""
immediate = f"""
You might be an knowledgeable in producing correct doc summaries.
Generate a abstract of the given doc.
Doc:
{doc}
Constraints: Please begin the abstract with the delimiter 'Abstract'
and restrict the abstract to five strains
Abstract:
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT

Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT

These are fairly good summaries throughout, though personally, I just like the abstract generated by GPT-4o and GPT-4o mini because it offers some minor however essential particulars, just like the time when this illness emerged.
Activity 9: Transformation
You should utilize LLMs to take an present doc and rework it into different codecs of content material and even generate coaching information for fine-tuning or coaching fashions
fact_sheet_mobile = """
PRODUCT NAME
Samsung Galaxy Z Fold4 5G Black
PRODUCT OVERVIEW
Stands out. Stands up. Unfolds.
The Galaxy Z Fold4 does quite a bit in a single hand with its 15.73 cm(6.2-inch) Cowl Display.
Unfolded, the 19.21 cm(7.6-inch) Major Display helps you to actually get into the zone.
Pushed-back bezels and the Below Show Digital camera means there's extra display screen
and no black dot getting between you and the breathtaking Infinity Flex Show.
Do greater than extra with Multi View. Whether or not toggling between texts or catching up
on emails, take full benefit of the expansive Major Display with Multi View.
PC-like energy due to Qualcomm Snapdragon 8+ Gen 1 processor in your pocket,
transforms apps optimized with One UI to provide you menus and extra in a look
New Taskbar for PC-like multitasking. Wipe out duties in fewer faucets. Add
apps to the Taskbar for fast navigation and bouncing between home windows when
you are within the groove.4 And with App Pair, one faucet launches as much as three apps,
all sharing one super-productive display screen
Our hardest Samsung Galaxy foldables ever. From the within out,
Galaxy Z Fold4 is made with supplies that aren't solely gorgeous,
however stand as much as life's bumps and fumbles. The entrance and rear panels,
made with unique Corning Gorilla Glass Victus+, are prepared to withstand
sneaky scrapes and scratches. With our hardest aluminum body made with
Armor Aluminum, that is one sturdy smartphone.
World’s first waterproof foldable smartphones. Be adventurous, rain
or shine. You do not have to sweat the forecast once you've obtained one of many
world's first water resistant foldable smartphones.
PRODUCT SPECS
OS - Android 12.0
RAM - 12 GB
Product Dimensions - 15.5 x 13 x 0.6 cm; 263 Grams
Batteries - 2 Lithium Ion batteries required. (included)
Merchandise mannequin quantity - SM-F936BZKDINU_5
Wi-fi communication applied sciences - Mobile
Connectivity applied sciences - Bluetooth, Wi-Fi, USB, NFC
GPS - True
Particular options - Quick Charging Assist, Twin SIM, Wi-fi Charging, Constructed-In GPS, Water Resistant
Different show options - Wi-fi
System interface - main - Touchscreen
Decision - 2176x1812
Different digicam options - Rear, Entrance
Kind issue - Foldable Display
Color - Phantom Black
Battery Energy Score - 4400
Whats within the field - SIM Tray Ejector, USB Cable
Producer - Samsung India pvt Ltd
Nation of Origin - China
Merchandise Weight - 263 g
"""
immediate =f"""Flip the next product description
into a listing of often requested questions (FAQ).
Present each the query and its corresponding reply
Generate on the max 5 however various and helpful FAQs
Product description:
```{fact_sheet_mobile}```
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT

Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT

All three fashions carry out the duty efficiently; nonetheless, it’s fairly clear that the standard of solutions generated by GPT-4o and GPT-4o mini is richer and extra detailed than the responses from GPT-3.5 Turbo.
Activity 10: Translation
You should utilize LLMs to translate an present doc from a supply to a goal language and to a number of languages concurrently. Right here, we’ll attempt to translate a bit of textual content into a number of languages and pressure the LLM to output a legitimate JSON response.
immediate = """You might be an knowledgeable translator.
Translate the given textual content from English to German and Spanish.
Present the output as key worth pairs in JSON.
Output ought to have all 3 languages.
Textual content: 'Good day, how are you in the present day?'
Translation:
"""response = get_completion(immediate, mannequin="gpt-3.5-turbo")
show(Markdown(response))OUTPUT

We are going to attempt subsequent with GPT-4o
response = get_completion(immediate, mannequin="gpt-4o")
show(Markdown(response))OUTPUT

Lastly, we attempt the identical job with the GPT-4o mini
response = get_completion(immediate, mannequin="gpt-4o-mini")
show(Markdown(response))OUTPUT

All three fashions carry out the duty efficiently, nonetheless, GPT-4o and GPT-4o mini generate a formatted JSON string as in comparison with GPT-3.5 Turbo
The Verdict
Whereas it is rather tough to say which LLM is best simply by taking a look at a number of duties, contemplating components like pricing, latency, multimodality, and high quality of outcomes throughout various duties, undoubtedly contemplate GPT-4o mini over GPT-3.5 Turbo. Nevertheless, GPT-4o might be nonetheless the mannequin with the best high quality of outcomes. As soon as once more, don’t go simply by face worth, attempt the fashions your self in your use-cases and make a last resolution. We didn’t contemplate different open SLMs like Llama 3, Gemma 2 and so forth, I might additionally encourage you to check GPT-4o mini to its different SLM counterparts!
Conclusion
On this information, we’ve an in-depth understanding of the options and efficiency of Open AI’s newly launched GPT-4o mini. We additionally did an in depth comparative evaluation of how GPT-4o mini fares in opposition to its predecessors, GPT-4o and GPT-3.5 Turbo, with a complete of ten completely different duties! Do take a look at this Colab pocket book for simple entry to the code and do check out GPT-4o mini, it is without doubt one of the most promising small language fashions to this point!
References:





{kind=link}