Introduction
Each week, new and extra superior Massive Language Fashions (LLMs) are launched, every claiming to be higher than the final. However how can we sustain with all these new developments? The reply is the LMSYS Chatbot Area.
The LMSYS Chatbot Area is an revolutionary platform created by the Massive Mannequin Methods Group, a bunch made up of scholars and lecturers from UC Berkeley, UCSD, and CMU. This platform makes it simple to check and consider completely different LLMs by permitting customers to check and price them. It’s a spot the place anybody excited about these fashions can come to search out out concerning the newest releases and see how they stack up in opposition to one another.
LMSYS Leaderboard
This leaderboard ranks varied LLMs utilizing a Bradley-Terry mannequin, with the rankings displayed on an Elo scale. The LMSYS leaderboard collects human pairwise comparisons to find out the rating. As of April 26, 2024, the leaderboard contains 91 completely different fashions and has collected greater than 800,000 human pairwise comparisons. The fashions are ranked primarily based on their efficiency in several classes, akin to coding and lengthy person queries. The rankings are displayed in Elo-scale, and the leaderboard is constantly up to date.
Click on right here to begin the stay testing of LLMs.
High 10 LLMs
The highest and trending fashions primarily based on Area Elo Scores are:
- GPT-4-Turbo by Open AI
- GPT-4-1106-preview by Open AI
- Claude 3 Opus by Anthropic
- Gemini 1.5 Professional API-0409-Preview by Google
- GPT-4-0125-preview by Open AI
- Bard (Gemini Professional) by Google
- Llama 3 70b Instruct by Meta
- Claude 3 Sonnet by Anthropic
- Command R+ by Cohere
- GPT-4-0314 by Open AI
Open AI is clearly profitable the race of finest LLMs up to now.
Now when you’re like me and questioning why there’s a time period preview in entrance of some fashions then right here is the reply – The time period “preview” usually refers to a model of a big language mannequin (LLM) that’s made accessible for testing, suggestions, or experimental use earlier than its official launch. This “preview” stage permits builders and customers to discover the mannequin’s capabilities, determine any points, and supply suggestions, which might be integrated into additional enhancements or refinements of the mannequin. Basically, it’s like a beta model of the software program, the place it’s largely useful and showcases new options or enhancements, however may nonetheless have some bugs or limitations that want addressing earlier than a full, steady launch.
The rankings bear in mind the 95% confidence interval when figuring out a mannequin’s rating, and fashions with fewer than 500 votes are faraway from the rankings.
Distinction between Open Supply vs Closed Supply LLMs
You may need heard that Llama 3 is the very best open supply Massive Language Mannequin (LLM) up to now. Nevertheless, when you examine the general rankings, GPT-4 Turbo is on the prime. Why is that? It’s as a result of the rankings embrace each open supply and closed supply LLMs.
Take a look at the final column of the leaderboard—it reveals the kind of license every LLM has. That is necessary as a result of it divides the fashions into two major teams: open supply and closed supply.

Open Supply LLMs
The code behind the Open Supply LLMs is publicly accessible. This enables anybody to examine, perceive, and even enhance the mannequin. This fosters a collaborative growth setting.
- Freely Out there: These fashions have permissive licenses like Apache 2.0 or MIT, permitting unrestricted use (e.g., Mixtral-8x22b-Instruct, Zephyr-ORPO, Starling-LM-7B-beta, OpenChat-3.5, Zephyr-7b-beta).
- Restricted Use: Some open-source fashions may need restrictions hooked up to their licenses. These restrictions might restrict industrial use (e.g., Artistic Commons licenses) or prohibit modifications (e.g., Copyleft licenses).(e.g., Command R+, Llama 3 ).
Closed Supply LLMs
LLMs that aren’t publicly accessible and require permission or licensing to make use of. These are usually developed by industrial entities. (e.g., OpenAI’s GPT-4 sequence, Google’s Gemini sequence, Anthropic’s Claude sequence).
In brief, open supply LLMs supply transparency and foster collaboration, whereas closed-source LLMs prioritize management and doubtlessly ship a extra polished person expertise.
How does LMSYS Area Works?
The LMSYS platform works by accumulating person dialogue knowledge to guage massive language fashions (LLMs). Customers can evaluate two completely different LLMs side-by-side on a given process after which vote on which LLM supplied a greater response. The LMSYS platform makes use of these votes to rank the completely different LLMs.
Right here’s a step-by-step breakdown of how LMSYS works:
- Go to LMSYS platform > ⚔️ Area (side-by-side) and choose any two completely different LLMs that you just need to evaluate.
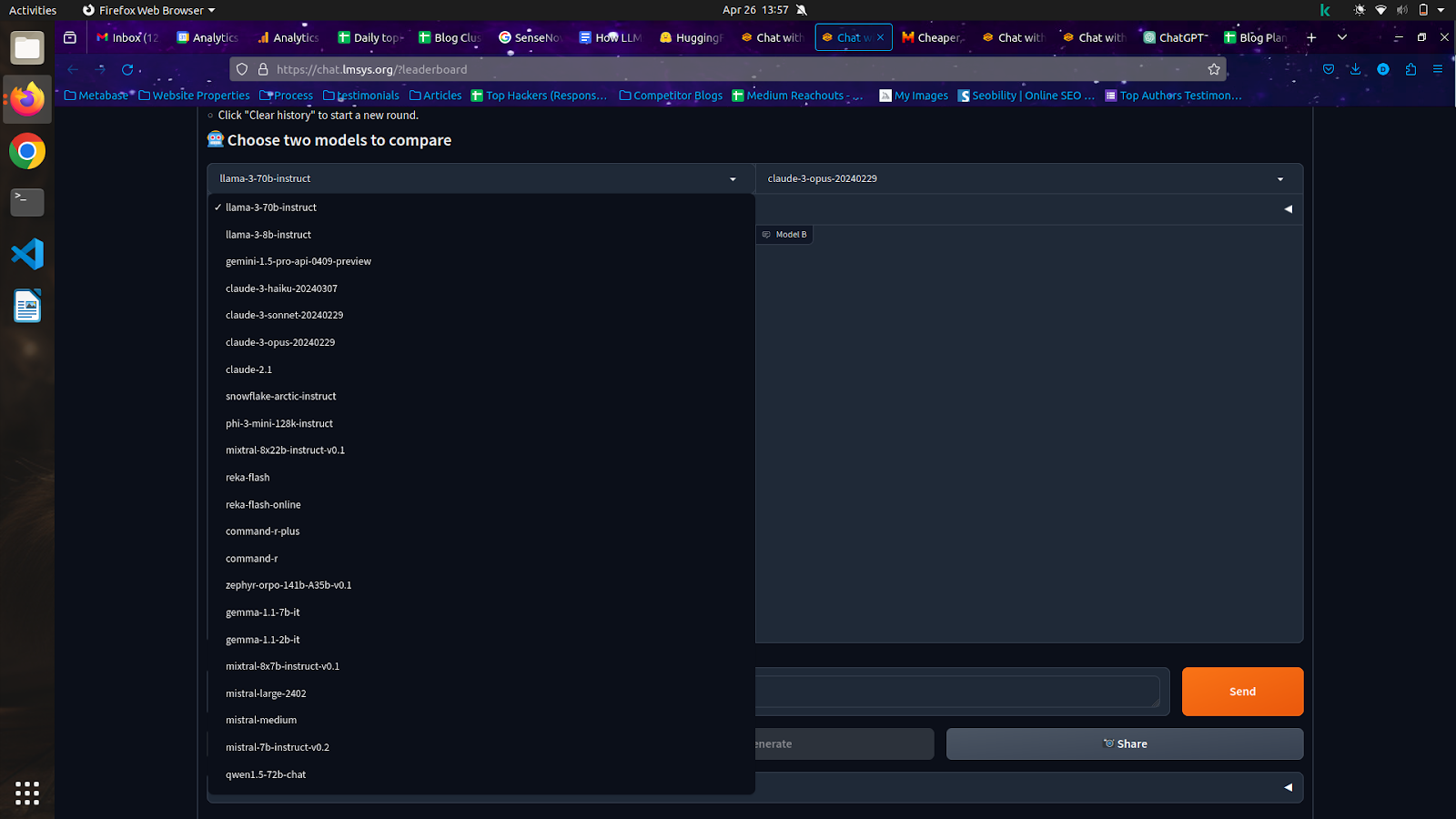
- Then present a process or immediate for the 2 LLMs to finish. This process might be something that may be evaluated by a human, akin to writing a poem, translating a language, or answering a query. Right here I requested the fashions: Write a 700 phrases article on High Open Supply LLMs.
- You’ll see two solutions from completely different LLMs aspect by aspect. Choose the one you like. When you don’t like both, you may choose “Each are dangerous” or “Tie”.

- The LMSYS platform will then use your vote to replace the rankings of the 2 LLMs. The particular approach by which the rankings are up to date relies on the Bradley-Terry mannequin, which is a statistical mannequin that can be utilized to rank gadgets primarily based on pairwise comparisons.
LMSYS Leaderboard Analysis System
The LMSYS leaderboard makes use of two major methods to price Massive Language Fashions (LLMs): the Elo score system and the Bradley-Terry mannequin.
- Elo Score System: This method, which can be utilized in chess, offers every LLM a rating primarily based on its efficiency. If an LLM wins a match, it good points factors, however it loses factors if it loses. The distinction in factors between two LLMs reveals which one is probably going stronger and extra prone to win in future matches.
- Bradley-Terry Mannequin: This methodology is a little more detailed than the Elo system. It appears to be like at issues like how robust the duties are that the LLMs deal with, giving a extra detailed take a look at how nicely every LLM performs.
Within the LMSYS Chatbot Area, LLMs are like gamers in a recreation, the place they work together with customers and compete in opposition to one another. Every LLM begins with a primary rating, and this rating modifications primarily based on whether or not they win or lose matches. Profitable in opposition to a stronger LLM offers extra factors, and shedding to a weaker one takes away extra factors. This fashion, the rankings at all times replicate the present strengths of the LLMs precisely.
The Elo system is nice for protecting monitor of how LLMs carry out over time, serving to to know which fashions are doing nicely and predicting how they may do sooner or later. This makes it a really great tool for seeing how new and current fashions stack up in opposition to one another within the ever-changing world of AI growth.
Interested by studying extra concerning the analysis course of, try their paper: https://arxiv.org/abs/2403.04132
Conclusion
I hope this text has helped you perceive how the LMSYS leaderboard works and the place you may hold monitor of the most recent developments in massive language fashions.
The LMSYS Chatbot Area makes use of a system the place customers assist rank the fashions, and it makes use of detailed strategies to attain them. This makes it an incredible place to essentially see how these fashions carry out. Understanding these fashions higher helps everybody use them extra successfully in real-life conditions.
If you recognize of another sources that may assist keep up-to-date within the discipline of Generative AI, please share them within the feedback part beneath. Your enter may help us all hold tempo with this quickly evolving expertise!
![]()
I’m a knowledge lover and I like to extract and perceive the hidden patterns within the knowledge. I need to be taught and develop within the discipline of Machine Studying and Information Science.





{kind=link}