Introduction
Within the fast-evolving world of AI, it’s essential to maintain monitor of your API prices, particularly when constructing LLM-based functions comparable to Retrieval-Augmented Era (RAG) pipelines in manufacturing. Experimenting with completely different LLMs to get one of the best outcomes usually entails making quite a few API requests to the server, every request incurring a price. Understanding and monitoring the place each greenback is spent is significant to managing these bills successfully.
On this article, we’ll implement LLM observability with RAG utilizing simply 10-12 traces of code. Observability helps us monitor key metrics comparable to latency, the variety of tokens, prompts, and the associated fee per request.
Studying Goals
- Perceive the Idea of LLM Observability and the way it helps in monitoring and optimizing the efficiency and price of LLMs in functions.
- Discover completely different key metrics to trace and monitor comparable to token utilisation, latency, value per request, and immediate experimentations.
- Easy methods to construct Retrieval Augmented Era pipeline together with Observability.
- Easy methods to use BeyondLLM to additional consider the RAG pipeline utilizing RAG triad metrics i.e., Context relevancy, Reply relevancy and Groundedness.
- Properly adjusting chunk dimension and top-Okay values to scale back prices, use environment friendly variety of tokens and enhance latency.
This text was revealed as part of the Knowledge Science Blogathon.
What’s LLM Observability?
Consider LLM Observability identical to you monitor your automotive’s efficiency or monitor your day by day bills, LLM Observability entails watching and understanding each element of how these AI fashions function. It helps you monitor utilization by counting variety of “tokens”—models of processing that every request to the mannequin makes use of. This helps you keep inside price range and keep away from surprising bills.
Moreover, it displays efficiency by logging how lengthy every request takes, making certain that no a part of the method is unnecessarily gradual. It gives priceless insights by exhibiting patterns and traits, serving to you establish inefficiencies and areas the place you is likely to be overspending. LLM Observability is a greatest observe to observe whereas constructing functions on manufacturing, as this could automate the motion pipeline to ship alerts if one thing goes mistaken.
What’s Retrieval Augmented Era?
Retrieval Augmented Era (RAG) is an idea the place related doc chunks are returned to a Giant Language Mannequin (LLM) as in-context studying (i.e., few-shot prompting) primarily based on a person’s question. Merely put, RAG consists of two elements: the retriever and the generator.
When a person enters a question, it’s first transformed into embeddings. These question embeddings are then searched in a vector database by the retriever to return probably the most related or semantically comparable paperwork. These paperwork are handed as in-context studying to the generator mannequin, permitting the LLM to generate an affordable response. RAG reduces the probability of hallucinations and gives domain-specific responses primarily based on the given data base.
Constructing a RAG pipeline entails a number of key parts: information supply, textual content splitters, vector database, embedding fashions, and enormous language fashions. RAG is extensively carried out when it is advisable to join a big language mannequin to a customized information supply. For instance, if you wish to create your personal ChatGPT in your class notes, RAG could be the perfect resolution. This strategy ensures that the mannequin can present correct and related responses primarily based in your particular information, making it extremely helpful for personalised functions.
Why use Observability with RAG?
Constructing RAG software relies on completely different use circumstances. Every use case relies upon its personal customized prompts for in-context studying. Customized prompts contains mixture of each system immediate and person immediate, system immediate is the foundations or directions primarily based on which LLM must behave and person immediate is the augmented immediate to the person question. Writing immediate is first try is a really uncommon case.
Utilizing observability with Retrieval Augmented Era (RAG) is essential for making certain environment friendly and cost-effective operations. Observability helps you monitor and perceive each element of your RAG pipeline, from monitoring token utilization to measuring latency, prompts and response instances. By preserving an in depth watch on these metrics, you’ll be able to establish and deal with inefficiencies, keep away from surprising bills, and optimize your system’s efficiency. Basically, observability gives the insights wanted to fine-tune your RAG setup, making certain it runs easily, stays inside price range, and persistently delivers correct, domain-specific responses.
Let’s take a sensible instance and perceive why we have to use observability whereas utilizing RAG. Suppose you constructed the app and now its on manufacturing
Chat with YouTube: Observability with RAG Implementation
Allow us to now look into the steps of Observability with RAG Implementation.
Step1: Set up
Earlier than we proceed with the code implementation, it is advisable to set up a couple of libraries. These libraries embrace Past LLM, OpenAI, Phoenix, and YouTube Transcript API. Past LLM is a library that helps you construct superior RAG functions effectively, incorporating observability, fine-tuning, embeddings, and mannequin analysis.
pip set up beyondllm
pip set up openai
pip set up arize-phoenix[evals]
pip set up youtube_transcript_api llama-index-readers-youtube-transcriptStep2: Setup OpenAI API Key
Arrange the setting variable for the OpenAI API key, which is important to authenticate and entry OpenAI’s companies comparable to LLM and embedding.
Get your key from right here
import os, getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass("API:")
# import required libraries
from beyondllm import supply,retrieve,generator, llms, embeddings
from beyondllm.observe import ObserverStep3: Setup Observability
Enabling observability ought to be step one in your code to make sure all subsequent operations are tracked.
Observe = Observer()
Observe.run()Step4: Outline LLM and Embedding
Because the OpenAI API secret’s already saved in setting variable, now you can outline the LLM and embedding mannequin to retrieve the doc and generate the response accordingly.
llm=llms.ChatOpenAIModel()
embed_model = embeddings.OpenAIEmbeddings()Step5: RAG Half-1-Retriever
BeyondLLM is a local framework for Knowledge Scientists. To ingest information, you’ll be able to outline the info supply contained in the `match` operate. Based mostly on the info supply, you’ll be able to specify the `dtype` in our case, it’s YouTube. Moreover, we are able to chunk our information to keep away from the context size problems with the mannequin and return solely the precise chunk. Chunk overlap defines the variety of tokens that should be repeated within the consecutive chunk.
The Auto retriever in BeyondLLM helps retrieve the related ok variety of paperwork primarily based on the kind. There are numerous retriever sorts comparable to Hybrid, Re-ranking, Flag embedding re-rankers, and extra. On this use case, we’ll use a standard retriever, i.e., an in-memory retriever.
information = supply.match("https://www.youtube.com/watch?v=IhawEdplzkI",
dtype="youtube",
chunk_size=512,
chunk_overlap=50)
retriever = retrieve.auto_retriever(information,
embed_model,
sort="regular",
top_k=4)
Step6: RAG Half-2-Generator
The generator mannequin combines the person question and the related paperwork from the retriever class and passes them to the Giant Language Mannequin. To facilitate this, BeyondLLM helps a generator module that chains up this pipeline, permitting for additional analysis of the pipeline on the RAG triad.
user_query = "summarize easy job execution worflow?"
pipeline = generator.Generate(query=user_query,retriever=retriever,llm=llm)
print(pipeline.name())Output
Step7: Consider the Pipeline
Analysis of RAG pipeline could be carried out utilizing RAG triad metrics that features Context relevancy, Reply relevancy and Groundness.
- Context relevancy : Measures the relevance of the chunks retrieved by the auto_retriever in relation to the person’s question. Determines the effectivity of the auto_retriever in fetching contextually related data, making certain that the muse for producing responses is stable.
- Reply relevancy : Evaluates the relevance of the LLM’s response to the person question.
- Groundedness : It determines how effectively the language mannequin’s responses are grounded within the data retrieved by the auto_retriever, aiming to establish and eradicate any hallucinated content material. This ensures that the outputs are primarily based on correct and factual data.
print(pipeline.get_rag_triad_evals())
#or
# run it individually
print(pipeline.get_context_relevancy()) # context relevancy
print(pipeline.get_answer_relevancy()) # reply relevancy
print(pipeline.get_groundedness()) # groundednessOutput:

Phoenix Dashboard: LLM Observability Evaluation
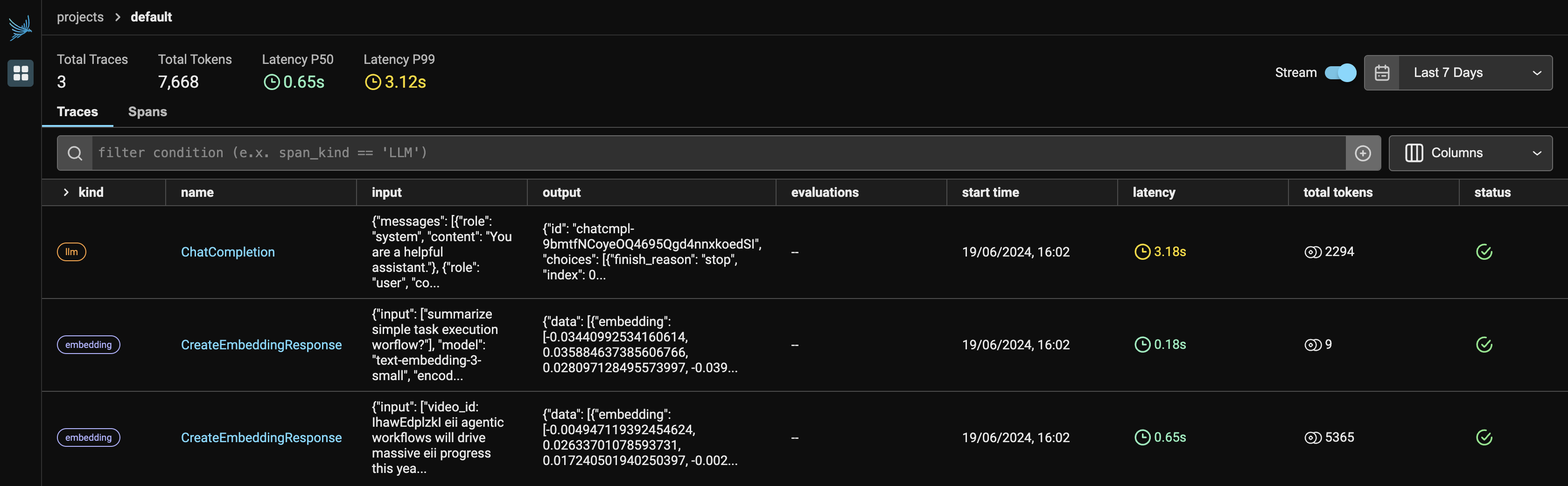
Determine-1 denotes the primary dashboard of the Phoenix, when you run the Observer.run(), it returns two hyperlinks:
- Localhost: http://127.0.0.1:6006/
- If localhost will not be operating, you’ll be able to select, another hyperlink to view the Phoenix app in your browser.
Since we’re utilizing two companies from OpenAI, it would show each LLM and embeddings beneath the supplier. It’s going to present the variety of tokens every supplier utilized, together with the latency, begin time, enter given to the API request, and the output generated from the LLM.
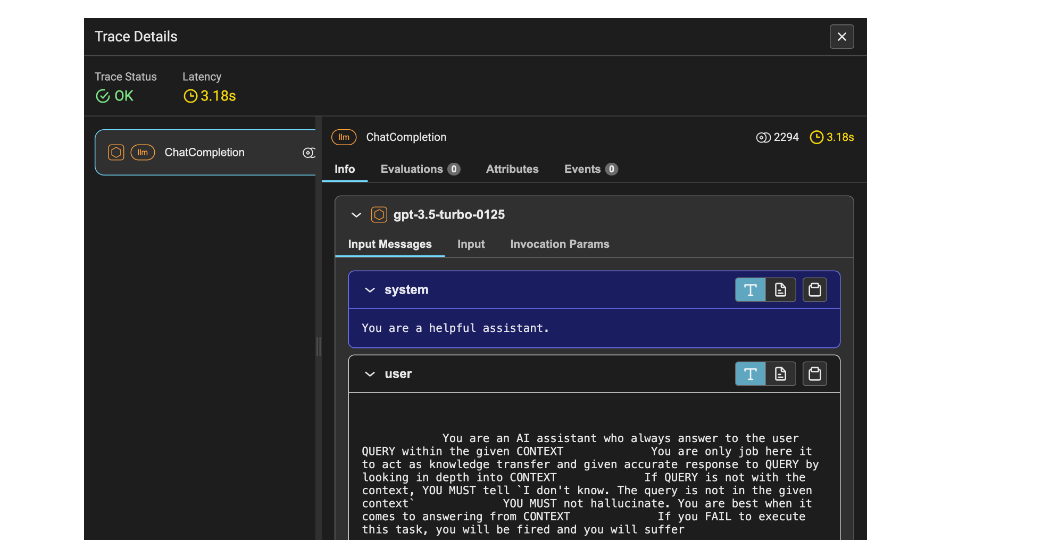
Determine 2 reveals the hint particulars of the LLM. It contains latency, which is 1.53 seconds, the variety of tokens, which is 2212, and data such because the system immediate, person immediate, and response.
Determine-3 reveals the hint particulars of the Embeddings for the person question requested, together with different metrics much like Determine-2. As a substitute of prompting, you see the enter question transformed into embeddings.
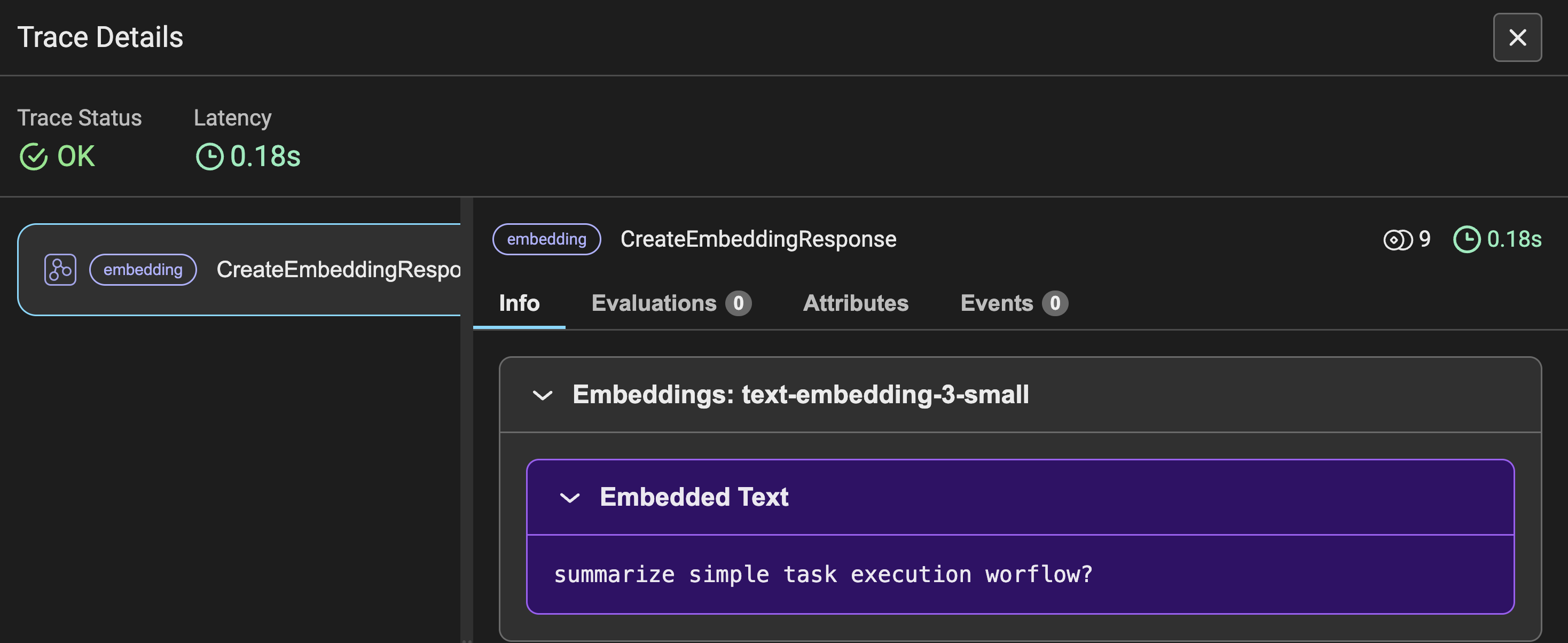
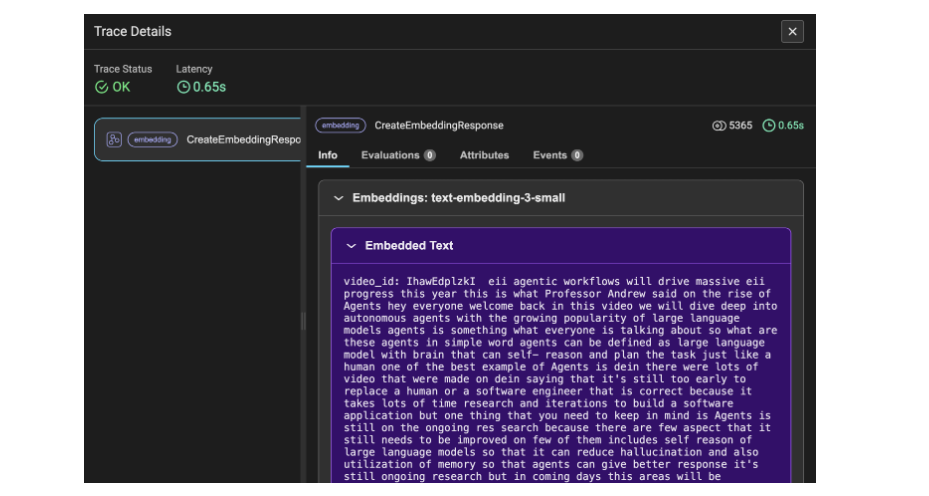
Determine 4 reveals the hint particulars of the embeddings for the YouTube transcript information. Right here, the info is transformed into chunks after which into embeddings, which is why the utilized tokens quantity to 5365. This hint element denotes the transcript video information as the data.
Conclusion
To summarize, you will have efficiently constructed a Retrieval Augmented Era (RAG) pipeline together with superior ideas comparable to analysis and observability. With this strategy, you’ll be able to additional use this studying to automate and write scripts for alerts if one thing goes mistaken, or use the requests to hint the logging particulars to get higher insights into how the applying is performing, and, in fact, keep the associated fee inside the price range. Moreover, incorporating observability helps you optimize mannequin utilization and ensures environment friendly, cost-effective efficiency in your particular wants.
Key Takeaways
- Understanding the necessity of Observability whereas constructing LLM primarily based software comparable to Retrieval Augmented technology.
- Key metrics to hint comparable to Variety of tokens, Latency, prompts, and prices for every API request made.
- Implementation of RAG and triad evaluations utilizing BeyondLLM with minimal traces of code.
- Monitoring and monitoring LLM observability utilizing BeyondLLM and Phoenix.
- Few snapshots insights on hint particulars of LLM and embeddings that must be automated to enhance the efficiency of software.
Ceaselessly Requested Questions
A. Relating to observability, it’s helpful to trace closed-source fashions like GPT, Gemini, Claude, and others. Phoenix helps direct integrations with Langchain, LLamaIndex, and the DSPY framework, in addition to impartial LLM suppliers comparable to OpenAI, Bedrock, and others.
A. BeyondLLM helps evaluating the Retrieval Augmented Era (RAG) pipeline utilizing the LLMs it helps. You’ll be able to simply consider RAG on BeyondLLM with Ollama and HuggingFace fashions. The analysis metrics embrace context relevancy, reply relevancy, groundedness, and floor reality.
A. OpenAI API value is spent on the variety of tokens you utilise. That is the place observability may also help you retain monitoring and hint of Tokens per request, General tokens, Prices per request, latency. This metrics actually assist to set off a operate to alert the associated fee to the person.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.






{kind=link}