Introduction
Retriever is an important a part of the RAG(Retrieval Augmented Era) pipeline. On this article, you’ll implement a customized retriever combining Key phrase and Vector search retriever utilizing LlamaIndex. Chat with A number of Paperwork utilizing Gemini LLM is the undertaking use case on which we are going to construct this RAG pipeline. To start with the undertaking, we are going to first perceive a number of crucial parts such because the Service and Storage context to construct such an software.
Studying Targets
- Acquire insights into the RAG pipeline, understanding the roles of Retriever and Generator parts in contextually producing responses.
- Be taught to combine Key phrase and Vector Search strategies to develop a customized retriever, enhancing search accuracy in RAG purposes.
- Purchase proficiency in using LlamaIndex for knowledge ingestion, offering context to LLMs, and deepening the connection to customized knowledge.
- Perceive the importance of customized retrievers in mitigating hallucinations in LLM responses by way of hybrid search mechanisms.
- Discover superior retriever implementations reminiscent of reranking and HyDE to reinforce doc relevance in RAG.
- Be taught to combine Gemini LLM and embeddings inside LlamaIndex for response technology and knowledge storage, enhancing RAG capabilities.
- Develop decision-making expertise for customized retriever configuration, together with deciding on between AND and OR operations for search consequence optimization.
This text was printed as part of the Information Science Blogathon.
What’s LlamaIndex?
The sphere of Massive Language Fashions is increasing quickly, enhancing considerably every day. With an growing variety of fashions being launched at a quick tempo, there’s a rising must combine these fashions with customized knowledge. This integration supplies companies, enterprises, and end-users with extra flexibility and a deeper connection to their knowledge.
LlamaIndex, initially often called GPT-index, is an information framework designed to your LLM purposes. As the recognition of constructing customized data-driven chatbots like ChatGPT continues to rise, frameworks like LlamaIndex develop into more and more helpful. At its core, LlamaIndex supplies numerous knowledge connectors to facilitate knowledge ingestion. On this article, we are going to discover how we are able to cross our knowledge as context to the LLM, this idea is what we imply by Retrieval Augmented Era, RAG briefly.
What’s RAG?
In Retrieval Augmented Era briefly RAG, there are two main parts: Retriever and Generator.
- Retriever could be the vector database, it’s job is to retrieve the related paperwork to the person question and cross it as a context to the immediate.
- Generator mannequin is a Massive Language mannequin, it’s job is to take the retrieved paperwork together with immediate to generate significant response from the context.
This manner RAG is the optimum answer for the in context studying through Automated Few shot prompting.
Significance of Retriever
Let’s perceive the significance of Retriever element in RAG pipeline.
To develop a customized retriever, it’s essential to find out the kind of retriever that most closely fits our wants. For our functions, we are going to implement a Hybrid Search that integrates each Key phrase Search and Vector Search.
Vector Search identifies related paperwork for a person’s question based mostly on similarity or semantic search, whereas Key phrase Search finds paperwork based mostly on the frequency of time period incidence.This integration could be achieved in two methods utilizing LlamaIndex. When constructing the customized retriever for Hybrid Search, a necessary resolution is selecting between utilizing an AND or an OR operation:
- AND operation: This method retrieves paperwork that embrace all the required phrases, making it extra restrictive however making certain excessive relevance. You possibly can think about this as intersection of outcomes between Key phrase Search and Vector Search.
- OR operation: This technique retrieves paperwork that include any of the required phrases, growing the breadth of outcomes however probably decreasing relevance. You possibly can assume this as union of outcomes between Key phrase Search and Vector Search.
Constructing Customized Retriever utilizing LLamaIndex
Allow us to now construct buyer retriever utilizing LlamaIndex. To construct this we have to comply with sure steps.
Step1: Set up
To get began with the code implementation on Google Colab or Jupyter Pocket book, one wants to put in the required libraries primarily in our case we are going to use LlamaIndex for constructing a customized retriever, Gemini for the embedding mannequin and LLM inference, and PyPDF for the information connector.
!pip set up llama-index
!pip set up llama-index-multi-modal-llms-gemini
!pip set up llama-index-embeddings-geminiStep2: Setup Google API key
On this undertaking, we are going to make the most of Google Gemini because the Massive Language Mannequin to generate responses and because the embedding mannequin to transform and retailer knowledge in vector-db or in-memory storage utilizing LlamaIndex.
Get your API key right here
from getpass import getpass
GOOGLE_API_KEY = getpass("Enter your Google API:")Step3: Load Information and Create Doc Node
In LlamaIndex, knowledge loading is achieved utilizing SimpleDirectoryLoader. First, you’ll want to create a folder and add knowledge in any format into this knowledge folder. In our instance, I’ll add a PDF file into the information folder. As soon as the doc is loaded, it’s parsed into nodes to separate the doc into smaller segments. A node is an information schema outlined inside the LlamaIndex framework.
The most recent model of LlamaIndex has up to date its code construction, which now consists of definitions for the node parser, embedding mannequin, and LLM inside the Settings.
from llama_index.core import SimpleDirectoryReader
from llama_index.core import Settings
paperwork = SimpleDirectoryReader('knowledge').load_data()
nodes = Settings.node_parser.get_nodes_from_documents(paperwork)Step4: Setup Embedding Mannequin and Massive Language Mannequin
Gemini helps numerous fashions, together with gemini-pro, gemini-1.0-pro, gemini-1.5, imaginative and prescient mannequin, amongst others. On this case, we are going to use the default mannequin and supply the Google API key. For the embedding mannequin in Gemini, we’re at the moment utilizing embedding-001. Be certain that a legitimate API key’s added.
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.gemini import Gemini
Settings.embed_model = GeminiEmbedding(
model_name="fashions/embedding-001", api_key=GOOGLE_API_KEY
)
Settings.llm = Gemini(api_key=GOOGLE_API_KEY)Step5: Outline Storage Context and Retailer Information
As soon as the information is parsed into nodes, LlamaIndex supplies a Storage Context, which provides default doc storage for storing the vector embeddings of the information. This storage context retains the information in-memory, permitting it to be listed later.
from llama_index.core import StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)Create Index- Key phrase and Index
For constructing the customized retriever to carry out hybrid search we have to create two indexes. First Vector Index that may carry out vector search, second Key phrase index that may carry out key phrase search. With a view to create the index, we required the storage context and the node paperwork, together with default Settings of embedding mannequin and LLM.
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndex
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)Step6: Assemble Customized Retriever
To assemble a customized retriever for hybrid search utilizing LlamaIndex, we first must outline the schema, particularly by appropriately configuring the nodes. For the retriever, each a Vector Index Retriever and a Key phrase Retriever are required. This permits us to carry out hybrid searches, integrating each strategies to reduce hallucinations. Moreover, we should specify the mode—both AND or OR—relying on how we need to mix the outcomes.
As soon as the nodes are configured, we question the bundle for every node ID utilizing each the vector and key phrase retrievers. Based mostly on the chosen mode, we then outline and finalize the customized retriever.
from llama_index.core import QueryBundle
from llama_index.core.schema import NodeWithScore
from llama_index.core.retrievers import (
BaseRetriever,
VectorIndexRetriever,
KeywordTableSimpleRetriever,
)
from typing import Listing
class CustomRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
keyword_retriever: KeywordTableSimpleRetriever,
mode: str = "AND") -> None:
self._vector_retriever = vector_retriever
self._keyword_retriever = keyword_retriever
if mode not in ("AND", "OR"):
elevate ValueError("Invalid mode.")
self._mode = mode
tremendous().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> Listing[NodeWithScore]:
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._keyword_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
keyword_ids = {n.node.node_id for n in keyword_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.replace({n.node.node_id: n for n in keyword_nodes})
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(keyword_ids)
else:
retrieve_ids = vector_ids.union(keyword_ids)
retrieve_nodes = [combined_dict[r_id] for r_id in retrieve_ids]
return retrieve_nodesStep7: Outline Retrievers
Now that the customized retriever class is outlined, we have to instantiate the retriever and synthesize the question engine. A Response Synthesizer is used to generate a response from an LLM based mostly on a person question and a given set of textual content chunks. The output from a Response Synthesizer is a Response object, that takes customized retriever as one of many parameter.
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)
# customized retriever => mix vector and key phrase retriever
custom_retriever = CustomRetriever(vector_retriever, keyword_retriever)
# outline response synthesizer
response_synthesizer = get_response_synthesizer()
custom_query_engine = RetrieverQueryEngine(
retriever=custom_retriever,
response_synthesizer=response_synthesizer,
)Step8: Run Customized Retriever Question Engine
Lastly, we’ve got developed our customized retriever that considerably reduces hallucinations. To check its effectiveness, we ran person queries together with one immediate from inside the context and one other from outdoors the context, then evaluated the responses generated.
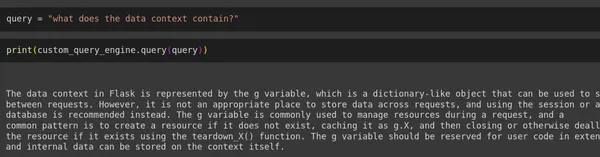
question = "what does the information context include?"
print(custom_query_engine.question(question))
print(custom_query_engine.question("what's science?"))Output

Conclusion
We’ve efficiently applied a customized retriever that performs Hybrid Search by combining Vector and Key phrase retrievers utilizing LlamaIndex, with the help of Gemini LLM and Embeddings. This method successfully reduces LLM hallucinations to some extent in a typical RAG pipeline.
Key Takeaways
- Growth of a customized retriever that integrates each Vector and Key phrase retrievers, enhancing the search capabilities and accuracy in figuring out related paperwork for RAG.
- Implementing Gemini Embedding and LLM utilizing LlamaIndex Settings, which is changed in newest model, beforehand this was accomplished utilizing Service Context, that’s now deprecated.
- In constructing the customized retriever, a key resolution is whether or not to make use of the AND or the OR operation, balancing the intersection and union of Key phrase and Vector Search outcomes in response to particular wants.
- The customized retriever setup helps considerably scale back hallucinations in Massive Language Mannequin responses through the use of a hybrid search mechanism inside the RAG pipeline.
Often Requested Questions
A. Hybrid Search is mainly a mix of key phrase type search and a vector type search. It has the benefit of doing key phrase search in addition to the benefit of doing a semantic lookup that we get from embeddings and a vector search.
A. In RAG retriever is every thing. If the related paperwork is just not returned to the Generator mannequin is sweet for nothing. With a view to scale back the hallucinations, context must correct. That is the place there are numerous technique to enhance the Retriever efficiency. Few of it consists of: Reranking, Hybrid Search, Sentence Window retrieval, HyDE and so forth.
A. Sure, Hybrid Search could be utilized in Langchain. In Langchain, we are able to outline algorithms reminiscent of BM25 or TFIDF because the key phrase retrievers and use a vector database as retriever for vector search. As soon as each retrievers are arrange, they are often built-in utilizing the Ensemble Retriever, which facilitates Hybrid Search in Langchain. This mixed method can then be fed into the RetrievalQA chain for question processing.
A. There are numerous vector databases able to internally integrating Hybrid Search by using vector search and eliminating the necessity for key phrase search. A few of these vector databases that help inner Hybrid Search embrace Qdrant, Weaviate, Elastic Search, amongst others.
Reference
https://docs.llamaindex.ai/en/steady/examples/query_engine/CustomRetrievers/
The media proven on this article is just not owned by Analytics Vidhya and is used on the Writer’s discretion.






{kind=link}