Please note: Most, if not all, of the articles published at this website were completed by Chat GPT (chat.openai.com) and/or copied and possibly remixed from other websites or Feedzy or WPeMatico or RSS Aggregrator or WP RSS Aggregrator. No copyright infringement is intended. If there are any copyright issues, please contact: bicycledays@yahoo.com.
AI voice technology has a significant downside. It really works like a robotic, studying a script phrase by phrase, with no emotions or feelings. It is perhaps intelligent, nevertheless it issues much less if there is no such thing as a human feeling connected to it. The best way the AI generates its voice makes it arduous to really feel such as you’re having a considerable dialog.
This all modified with Google DeepMind releasing the Gemini 3.1 Flash TTS on April 15, 2026. This TTS isn’t just a sophisticated speech synthesizer, nevertheless it additionally now features as an AI speech director!
This know-how means that you can create a voice actor studio with none actual tools, just by utilizing an API name or in Google Studio. Now, allow us to have a look at the brand new options of this know-how, what it means to you, and most significantly, three real-world initiatives you would create and use instantly with it!
What Makes Gemini 3.1 Flash TTS Totally different?
In earlier variations of AI TTS, the one possibility for you was fundamental voice and velocity management. The Gemini 3.1 Flash TTS is a big enhancement over earlier generations and supplies a bunch of latest options.
The brand new options obtainable with Gemini 3.1 Flash TTS embody:
Audio Tags: Add Pure Language “Stage Instructions” into your transcript. For instance, telling the mannequin to sound like they’re excited, to whisper a secret, or to pause earlier than persevering with will consequence within the mannequin performing as requested.
Scene Instructions: Outline the Environmental and Narrative context for the complete script, guaranteeing that characters stay in character for a number of successive dialogue items routinely.
Character Profiles: Set up distinctive, up-to-date audio profiles for every character. Apply your Director’s Notes to set the supply of every character’s Audio Profile with respect to: Tempo, Tone and Accent.
Inline Pivot Tags: Audio system can quickly change from Regular to Panicked with out the necessity for a separate API name, even when it’s halfway via a dialogue.
Exportable Settings: As soon as the voice has been configured, export the precise configuration to the Gemini API code for instant use.
Each audio file created with Gemini 3.1 is embedded with “SynthID”, an invisible audio signature developed by Google DeepMind to assist monitor the utilization of artificial audio recordsdata. It mainly supplies a technique of detecting artificial audio from historically produced audio recordsdata.
Getting Began with Gemini 3.1 Flash TTS
The Gemini 3.1 Flash TTS has three obtainable accessible platforms at present:
Developer customers can preview via Gemini’s API and the Google AI Studio
Enterprise customers can preview via Vertex AI
Google Vids is obtainable to Workspace customers solely
For the 2 examples that make the most of API know-how under, please you should definitely get a free Gemini API Key to make use of by visiting aistudio.google.com. The third instance would require only a internet browser to entry.
App 1: Construct an Emotional Audiobook Narrator utilizing Gemini API
In our real-world check of the Gemini 3.1 Flash TTS, we will construct a Python program for changing plain textual content tales to audiobooks with distinct sounds of emotion utilizing audio tags. That is how audio tags can drastically enhance the standard of the TTS audio within the audiobook course of. Audiobook TTS typically has a monotonous tone; nonetheless, whenever you management the feelings via the audio tags per scene, there must be a noticeable distinction within the audio output.
Directions:
1. Set up the Gemini Python SDK:
pip set up google-generativeai
2. Create a file named audiobook.py and paste within the following code:
import google.generativeai as genai
import base64
genai.configure(api_key="YOUR_API_KEY")
story = """
[calm, slow, hushed narrator voice]
The outdated home had been empty for thirty years.
[building tension, slight tremor in voice]
As she pushed open the door, the floorboards groaned beneath her.
[sharp, alarmed, fast-paced]
Then she noticed it. A shadow. Shifting towards her.
[relieved exhale, warm and soft]
It was simply the cat. An outdated tabby, blinking up at her at nighttime.
"""
consumer = genai.Shopper()
response = consumer.fashions.generate_content(
mannequin="gemini-3.1-flash-tts-preview",
contents=story,
config={
"response_modalities": ["AUDIO"],
"speech_config": {
"voice_config": {
"prebuilt_voice_config": {"voice_name": "Kore"}
}
}
}
)
audio_data = response.candidates[0].content material.components[0].inline_data.knowledge
wav_bytes = base64.b64decode(audio_data)
with open("audiobook_output.wav", "wb") as f:
f.write(wav_bytes)
print("Saved: audiobook_output.wav")
3. Change the placeholder of “YOUR_API_KEY” with your individual API KEY and run this system
python audiobook.py
4. Open and hearken to the audio file situated at audiobook_output.wav
The stage instructions present in brackets will point out how the narrator ought to emotionally interpret every chapter of an audiobook. For instance, by studying every chapter, the narrator will go from a peaceful whisper to confusion and panic, adopted by a peaceful reduction in a single steady audio recording.
Output:
Enhance it additional: Discover any chapter from the Challenge Gutenberg web site and use it within the audiobook; then loop via the paragraph in a chapter. You may as well tag the sentiment for every paragraph utilizing the sentiment audio tags to create your individual audiobooks. By this technique, it’s best to be capable to create an immediate and expressive audiobook with little or no studio time required.
App 2: Multi-Character Podcast Generator utilizing Gemini API
On this test-case, we are going to use the multi-speaker/host function of Gemini 3.1 Flash Textual content-to-Speech. For this, we are going to construct a podcast script with two voices (two separate speeds, tones, and attitudes) from one single API name inside the similar audio file.
Apparently, there is no such thing as a want to attach 2 API calls, and there’s no want for post-production for this. Simply present a single immediate that may convert to 2 separate personalities right into a single audio file.
Directions:
1. Create a script referred to as podcast_gen.py
import google.generativeai as genai
import base64
genai.configure(api_key="YOUR_API_KEY")
transcript = """
<scene>
Two tech journalists debate whether or not AI voice is overhyped.
Alex is skeptical and speaks rapidly with a dry tone.
Jordan is enthusiastic, heat, and barely sooner when excited.
</scene>
<speaker identify="Alex" tempo="quick" tone="dry, skeptical">
Yearly somebody declares that is the AI voice breakthrough.
And yearly, the demos sound nice however actual adoption drags.
</speaker>
<speaker identify="Jordan" tempo="measured" tone="enthusiastic, heat">
However this time the numbers again it up. We're not speaking demos —
we're speaking manufacturing deployments delivery precise product.
</speaker>
<speaker identify="Alex" tone="sharp, sardonic">
Deployments of chatbots that also mispronounce "Worcestershire."
Unbelievable milestone.
</speaker>
<speaker identify="Jordan" tone="laughing, gentle">
Okay, truthful. However the trajectory — you genuinely can not argue
with the place that is heading in twelve months.
</speaker>
"""
consumer = genai.Shopper()
response = consumer.fashions.generate_content(
mannequin="gemini-3.1-flash-tts-preview",
contents=transcript,
config={
"response_modalities": ["AUDIO"],
"speech_config": {
"multi_speaker_voice_config": {
"speaker_voice_configs": [
{
"speaker": "Alex",
"voice_config": {
"prebuilt_voice_config": {"voice_name": "Fenrir"}
}
},
{
"speaker": "Jordan",
"voice_config": {
"prebuilt_voice_config": {"voice_name": "Aoede"}
}
}
]
}
}
}
)
audio_data = response.candidates[0].content material.components[0].inline_data.knowledge
wav_bytes = base64.b64decode(audio_data)
with open("podcast.wav", "wb") as f:
f.write(wav_bytes)
print("Podcast saved: podcast.wav")
2. Execute it by executing the instructions proven under:
python podcast_gen.py
3. Open podcast.wav file and hearken to the 2 distinct voices representing the 2 personalities (the audio recordings may have been created with out using a recording studio).
Output:
Enhance it additional: To broaden upon this, level an internet scrape software at any article you discover in a information supply or Reddit thread, create a 10-line abstract that converts that article right into a two-host debate-style script, and ship this to your podcast_gen.py. Now you’ll have an automatic “AI Each day Information Podcast” that may run day by day out of your crontab.
App 3: Direct a Film Trailer Voice-Over utilizing Google AI Studio
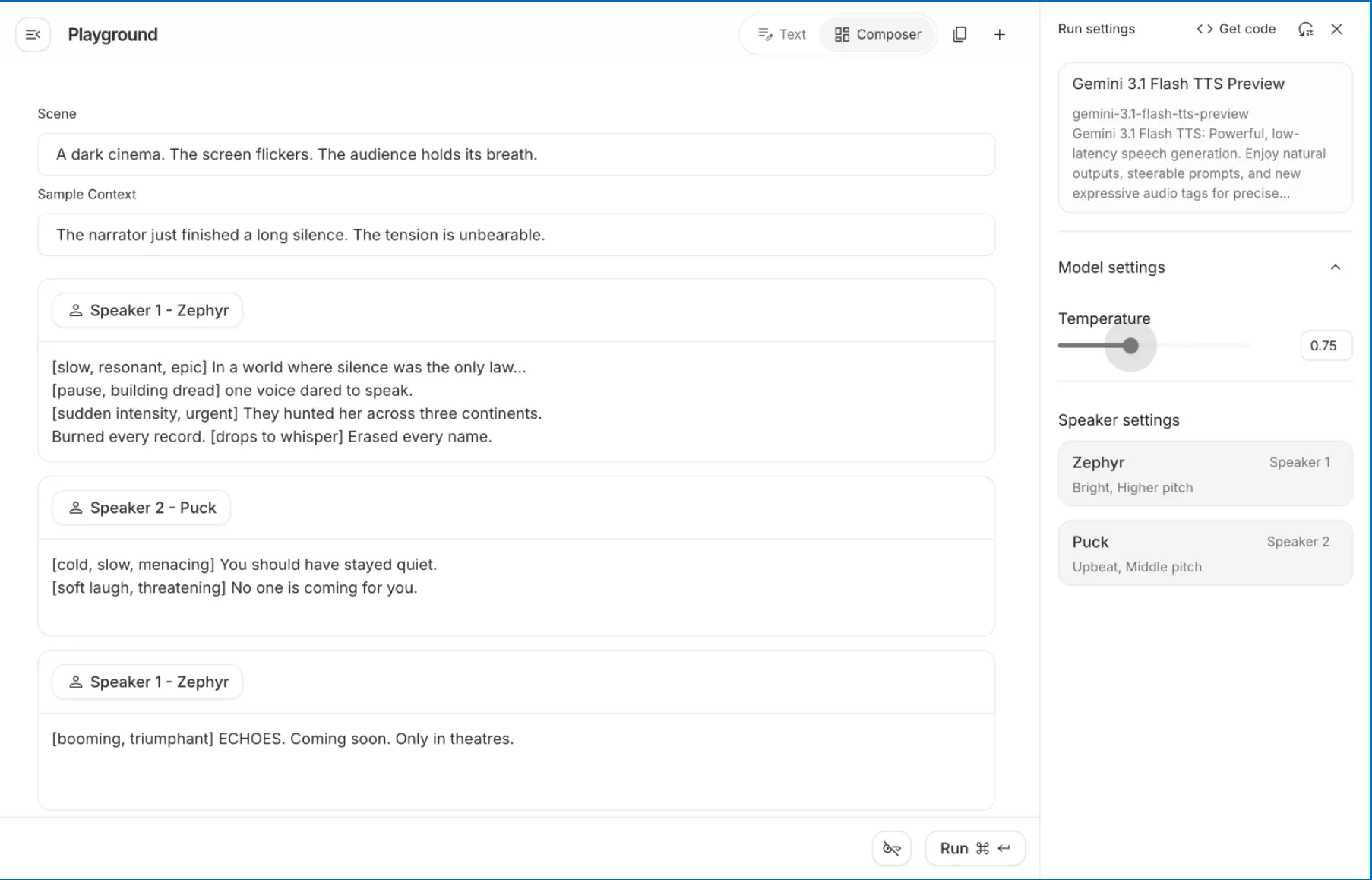
The Banana Break up & Liberty Bell are collaborating to current you with a shocking film trailer voice-over. You can be doing every thing via the Google AI Studio browser console; due to this fact, there is no such thing as a want for coding or extra setup. You’ll really feel fully artistic on this mission, as you grow to be the artistic director for this mission.
There are three components to this, and they’re as follows:
Prepared the Mannequin
1. Go to aistudio.google.com. As soon as there, log in along with your Google account. You’ll not want a bank card for the free-tier use of the service.
2. Select the Mannequin. As soon as logged in, choose the Gemini-3 TTS Preview. It is going to be titled on the right-hand sidebar underneath “Run Settings.”
Set the Scene
3. Use the textual content under to create a scene within the offered textbox on the high of the Google AI Playground, earlier than you choose the masculine or female voice(s):
A darkish film theatre. The display screen sparkles. The viewers is holding their breath.
This can give the mannequin a context wherein to keep up character for all of the audio system all through the manufacturing.
4. Create your Pattern Context. On this space kind: The narrator has simply accomplished a protracted silence. The bodily pressure is at an unbelievable degree.
This tells the mannequin what kind of emotional state existed previous to the primary line of dialogue getting used.
Full Speaker Profiles
5. Full Speaker 1 – Zeph’s (Narrator) dialogue. Within the panel, you will note that Zephyr is designated as Speaker 1, with the descriptors of “Vivid, Greater pitch.” This means that he’s to be an pressing and charming narrator, good for an epic storyteller. Within the Speaker 1 dialogue block, kind the next:
[slow, deep, dramatic] In a world the place silence is taken into account “the legislation”,
[pause, building anxiety] one voice dares to talk.
[suddenly urgent, with intensity] They hunted her throughout the globe, and destroyed every thing they discovered.
[drops the intensity] Disappeared by any means crucial.
Full Speaker 2 – Puck’s (Villain) dialogue. You will note that Puck has beforehand been designated as “Upbeat, Center pitch”; nonetheless, you may overwrite that vitality with a temper tag. Within the Speaker 2 dialogue block, kind the next:
[cold, slow, with a menacing air] You need to have by no means spoken.
[softly laughing, threat] There isn’t a one else coming that will help you.
Click on on “+ Add Speech Block” so as to add one other narrative closing for Speaker Zephyr’s narrative phase on the finish of this phase, and kind:
[booming, heroic voice] ECHOES. Coming quickly. Solely in theatres.
Output:
Benchmarks: How Does It Really Stack Up?
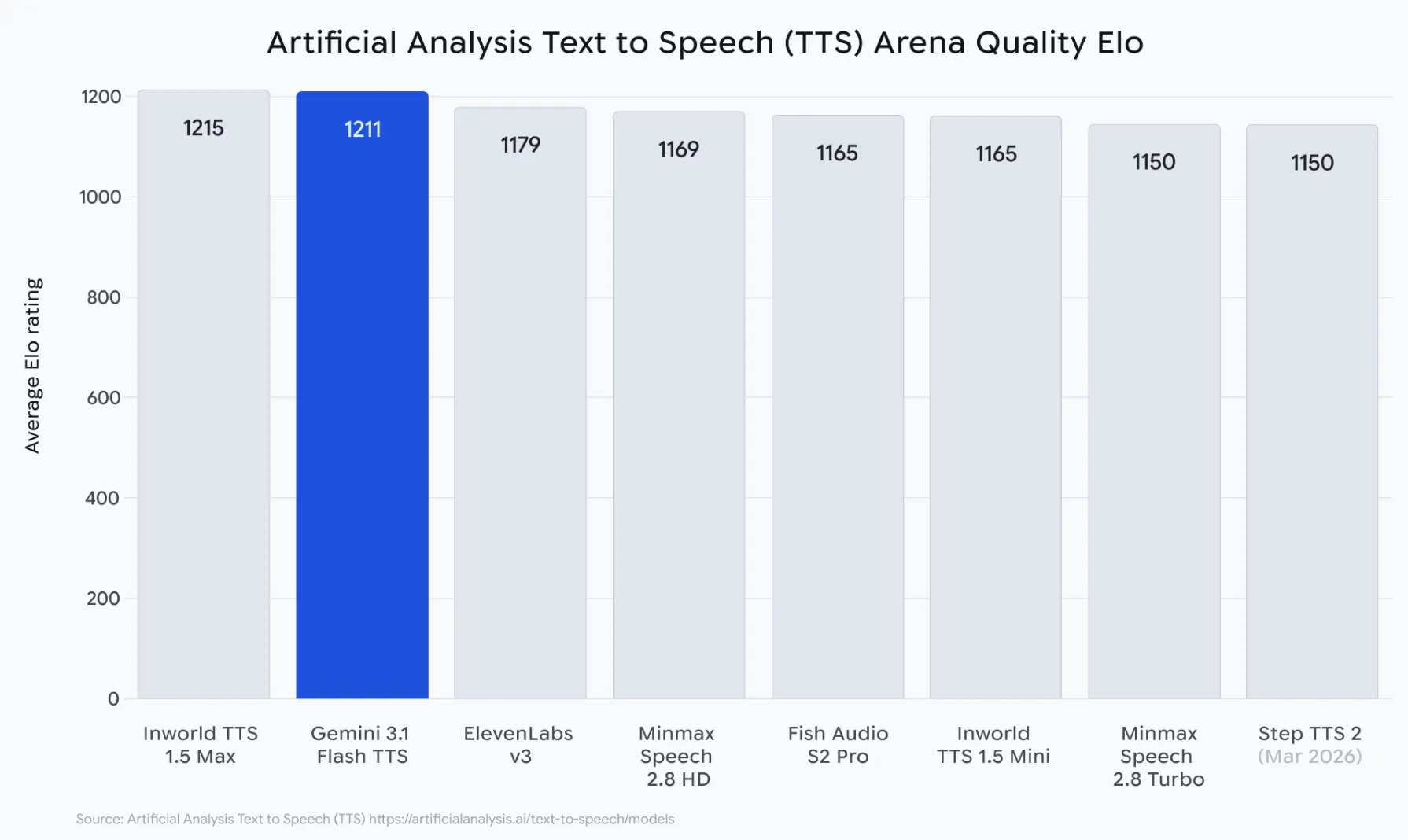
At this level, we will see a wholly completely different aspect to the story. Whereas Google doesn’t say they’re higher than everybody else, they did submit their Gemini 3.1 Flash TTS (Textual content to Speech) to essentially the most thorough impartial benchmark TTS ever created.
The Synthetic Evaluation TTS Enviornment runs 1000’s of nameless blind human choice checks on artificial speech. In these checks, individuals hear to 2 TTS voices and choose the one they consider sounds essentially the most pure, with out understanding which mannequin produced which voice. There isn’t a cherry-picking of samples or scores made by the corporate itself. That is the last word demonstration of how many individuals will favor utilizing every voice within the market. Listed here are a few of the outcomes of the Gemini 3.1 Flash TTS robotic:
1,211 Elo Rating at launch – the very best Elo rating for all publicly obtainable TTS engines
“Most Enticing Change” placement – the one TTS within the historical past of TTS with each excessive naturalness and low value per character
70+ languages examined – all maintained natural-sounding model, pacing, and accent management
Produced three or extra completely different audio system in a single coherent output — not produced from concatenated clips
watermarked with SynthID within the output of every voice; no different mannequin on the leaderboard watermarks with SynthID.
Gemini 3.1 Flash TTS Comparability with Opponents
Most high-quality TTS engines aren’t reasonably priced. Most low-cost TTSes sound like TTSes that value an excessive amount of. Gemini 3.1 Flash TTS is the primary TTS to confidently place itself between these fashions. Right here’s the way it stacks up in opposition to the main AI TTS fashions throughout standards that matter:
Function
Gemini 3.1 Flash TTS
ElevenLabs Multilingual v3
OpenAI TTS HD
Azure Neural TTS
Elo Rating (Synthetic Evaluation)
1,211
~1,150 (est.)
~1,090 (est.)
~1,020 (est.)
Audio Tags / Emotion Management
Native, inline
Voice cloning solely
None
SSML tags solely
Multi-Speaker Dialogue
Native, single name
Requires stitching
Requires stitching
Restricted
Language Assist
70+ languages
32 languages
57 languages
140+ languages
Accent + Tempo Management
Per-speaker, pure language
By way of voice cloning
No
SSML solely
Scene / Context Course
Sure
No
No
No
AI Security Watermarking
SynthID
No
No
No
Export as API Code
One-click in AI Studio
No
No
No
Free Tier / Playground
Google AI Studio
Restricted trial
Playground
Restricted trial
Greatest For
Artistic + expressive apps
Voice cloning initiatives
Easy, clear narration
Enterprise scale
Conclusion
AI voice know-how has been round for a very long time, and it has been “ok” for a lot of makes use of. Nonetheless, AI voices weren’t “ok” for utilization in contexts that require a human voice to painting emotion, or to supply the consumer any type of artistic management.
Gemini 3.1 Flash TTS adjustments all of that. The wealthy set of options makes it the very first AI-based speech mannequin that may actually compete with a recorded human voice, particularly to be used in artistic functions.
The three initiatives above are simply your entry level. Suppose interactive fiction with branching voiced narratives, multilingual customer support brokers with regional accents, and even AI tutors that sound like they care. With Gemini 3.1 Flash TTS, the sky is the restrict.
Technical content material strategist and communicator with a decade of expertise in content material creation and distribution throughout nationwide media, Authorities of India, and personal platforms
Login to proceed studying and luxuriate in expert-curated content material.
{kind=link}



")
