Acquiring the textual content in a messy PDF file is extra problematic than it’s useful. The issue doesn’t lie within the potential to rework pixels into textual content, however moderately, in sustaining the construction of the doc. Tables, headings, and pictures needs to be in the appropriate sequence. When utilizing Mistral OCR 3, it’s not the textual content conversion, however the manufacturing of enterprise usable info. The brand new AI-powered doc extraction software will probably be meant to reinforce sophisticated file extraction.
This information discusses the Mistral OCR 3 mannequin. We’ll additionally talk about its new options and their strategies of utilization, and eventually, conclude with a comparability with the open-weights DeepSeek-OCR mannequin as nicely.
Understanding Mistral OCR 3
Mistral presents its new software OCR 3 as a general-purpose one. It offers with the massive variety of paperwork current in organizations, and isn’t restricted to OCRing clear scans of invoices. Mistral offers crucial enhancements that clear up among the frequent failures of OCR.
- Handwriting: The mannequin will get improved work on printing and handwriting of textual content on printers.
- Varieties: It processes sophisticated constructions of packing containers, labels, and blended forms of texts. It’s typical of invoices, receipts, and authorities paperwork.
- Scanned Paperwork: The system is much less affected by scanning artifacts resembling skew, distortion, low decision, and so on.
- Advanced Tables: It gives an improved desk of reconstruction. This can embody a mixture of cells, in addition to multi-rows. The output is in HTML tags to be able to keep the unique format.
Mistral says that it examined the mannequin towards inside benchmarks, which imply actual enterprise instances.
What’s New in OCR 3?
The ultimate launch presents two important modifications to builders: high quality of the output and management. These traits amplify organized extraction powers of the mannequin.
1. New Controls for Doc Parts: The changelog of the Mistral OCR 3 associates the brand new mannequin with novel parameters and outputs. Tableformat is now in a position to choose between markdown and HTML. Extractheader, extractfooter, and hyperlinks may also assist in the dealing with of particular doc sections. This is without doubt one of the foundations of its doc AI system.
2. A UI Playground for Quick Testing: Mistral OCR 3 has its OCR API and a “Doc AI Playground” in Mistral AI Studio. A playground lets you take a look at difficult situations expediently, e.g. defective scans or scribbles. Earlier than automating your course of, you may modify such parameters as desk format and test outputs. Profitable OCR initiatives ought to have a suggestions loop that’s quick.
3. Backward Compatibility: Mistral confirms that OCR 3 is appropriate with the remainder of its earlier model. This can allow groups to modernize their programs over time with out re-writing their pipeline.
Fashions and Pricing
The OCR 3 is alleged to be mistral-ocr-2512. The documentation additionally refers to a mistral-ocr-latest alias. Pricing will probably be executed on a web page foundation.
- $2 per 1000 pages
- $3 per 1000 annotated pages
The second worth could be if you find yourself utilizing annotations to do structured extraction. This price needs to be put within the price range early by the groups.
Arms-on with the Doc AI Playground
You’ll be able to entry Mistral OCR 3 by the Doc AI Playground in Mistral AI Studio. This enables for fast, sensible testing.
- Open the Doc AI Playground in Mistral AI Studio. Head over to console.mistral.ai/construct/document-ai/ocr-playground
If you happen to see “Choose a plan”, then enroll utilizing your quantity and it is possible for you to to see the next
- Add a PDF or picture file. Begin with a difficult doc, like a scanned type with a desk.
Why this picture?
A clear bill with a desk (nice first take a look at for OCR 3 desk reconstruction)
Use this to test:
- studying order (header fields vs line gadgets)
- desk extraction (rows/columns, totals)
- header/footer extraction
- Choose the OCR 3 mannequin, which can be
mistral-ocr-2512or newest. - Select a desk format. Use html for structural accuracy or markdown in case your pipeline makes use of it.

- Run the method and examine the output. Test the studying order and desk construction.
Output:
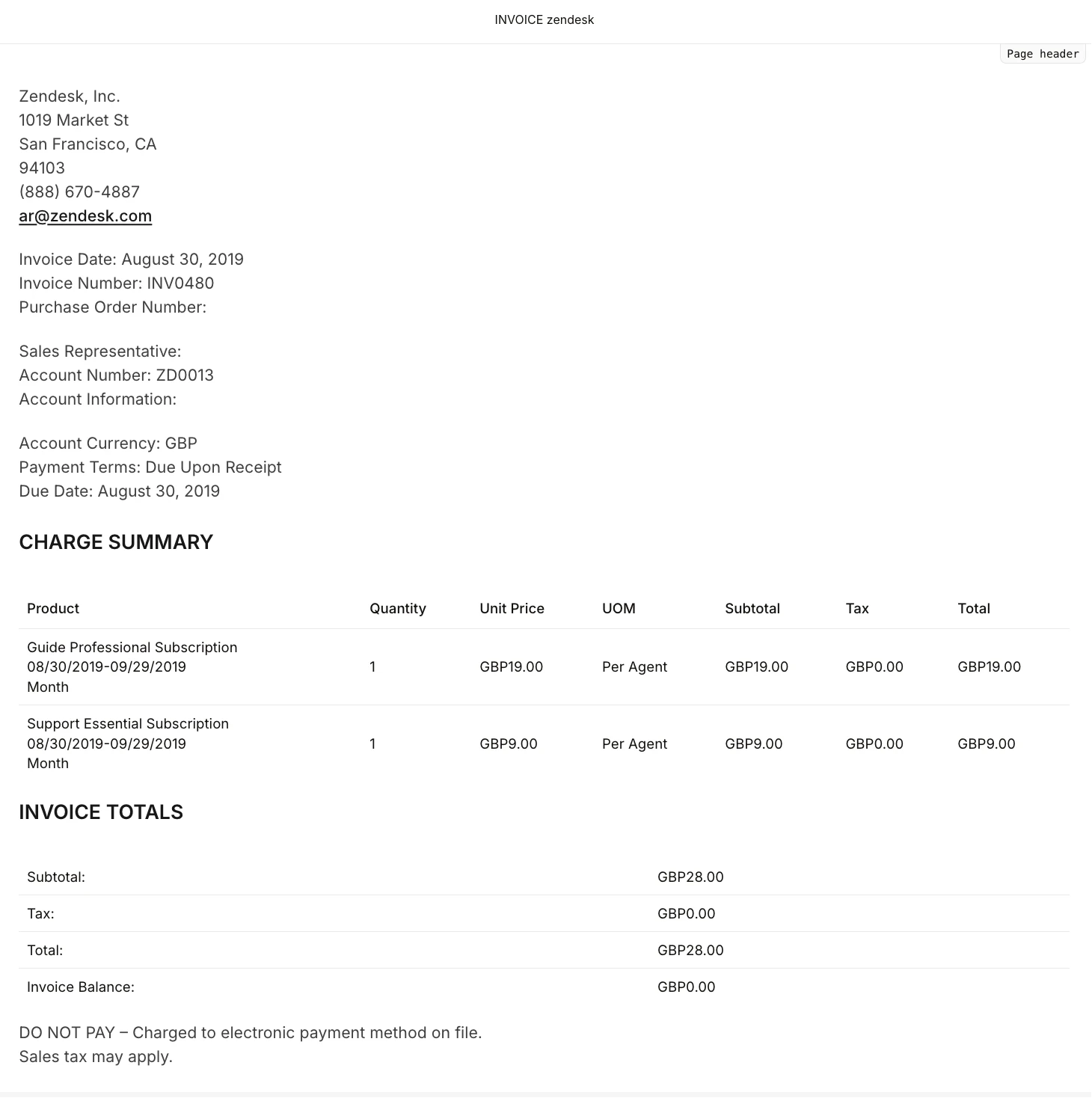
- This primary OCR 3 run is basically flawless for a clear digital bill.
- All key fields, format sections, and the cost abstract desk are captured accurately with no textual content errors or hallucinations.
- Desk construction and numeric consistency are preserved, which is important for monetary automation.
- It reveals OCR 3 is production-ready out of the field for normal invoices.
Arms-on with the OCR API
Possibility A: OCR a Doc from a URL
The OCR API helps doc URLs. It returns textual content and structured components.
Here’s a Python instance utilizing the official SDK.
import os
from mistralai import Mistral, DocumentURLChunk
consumer = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
resp = consumer.ocr.course of(
mannequin="mistral-ocr-2512",
doc=DocumentURLChunk(document_url="https://arxiv.org/pdf/2510.04950"),
table_format="html",
extract_header=True,
extract_footer=True,
)
print(resp.pages[0].markdown[:1000])Output:

Possibility B: Add Recordsdata and OCR by file_id
This technique works for personal paperwork, not on a public URL. Mistral’s API has a /v1/recordsdata endpoint for uploads.
First, add the file utilizing Python.
import os
from mistralai import Mistral
consumer = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
uploaded = consumer.recordsdata.add(
file={"file_name": "doc.pdf", "content material": open("/content material/Resume-Pattern-1-Software program-Engineer.pdf", "rb")},
goal="ocr",
)
resp = consumer.ocr.course of(
mannequin="mistral-ocr-2512",
doc={"file_id": uploaded.id},
table_format="html",
)
print(resp.pages[0].markdown[:1000])Output:
Dealing with Photos and Tables
Photos and tables within the markdown are characterised by placeholders utilized by OCR output of Mistral. The actual content material that’s extracted is given again in several arrays. This format offers you an choice to have the markdown as the first doc view. The image and desk assets can then be saved within the required location.
Easy OCR is step one. Structured Extraction offers the actual worth. The function of concept annotations is offered within the doc AI platform by Mistral. It lets you create a schema and unstructure paperwork with JSON. That’s the way you give you reliable extraction pipelines which can’t be damaged by altering an bill format by a vendor. One answer is extra sensible which is to make use of OCR 3 to enter textual content and annotations to the actual fields you require, e.g. bill numbers or totals.
Scaling Up with Batch Inference
In excessive quantity processing, a batching is required. The batch system by Mistral lets you submit a lot of API requests in a file with a.jsonl extension. They’ll then be run as one job. The documentation signifies that /v1/ocr is without doubt one of the supported batch jobs endpoints.
Find out how to Select the Proper Mannequin
The only option will depend on your paperwork and constraints. Here’s a clear method to consider.
What to Measure
- Textual content Accuracy: Use character or phrase error charges on pattern pages.
- Construction High quality: Rating desk reconstruction and studying order correctness.
- Extraction Reliability: Measure area accuracy on your goal information factors.
- Operational Efficiency: Monitor latency, throughput, and failure modes.
Let’s Examine
Use the next picture because the reference to check the each fashions. We chosen this picture as it’s:
A tough stress-test type with boxed fields + blended handwriting + printed textual content (nice for evaluating OCR 3 vs DeepSeek-OCR).
We are going to use this to check:
- handwriting accuracy (cursive + digits)
- field/area alignment (numbers inside little squares)
- robustness to dense layouts and small textual content
Mistral OCR 3
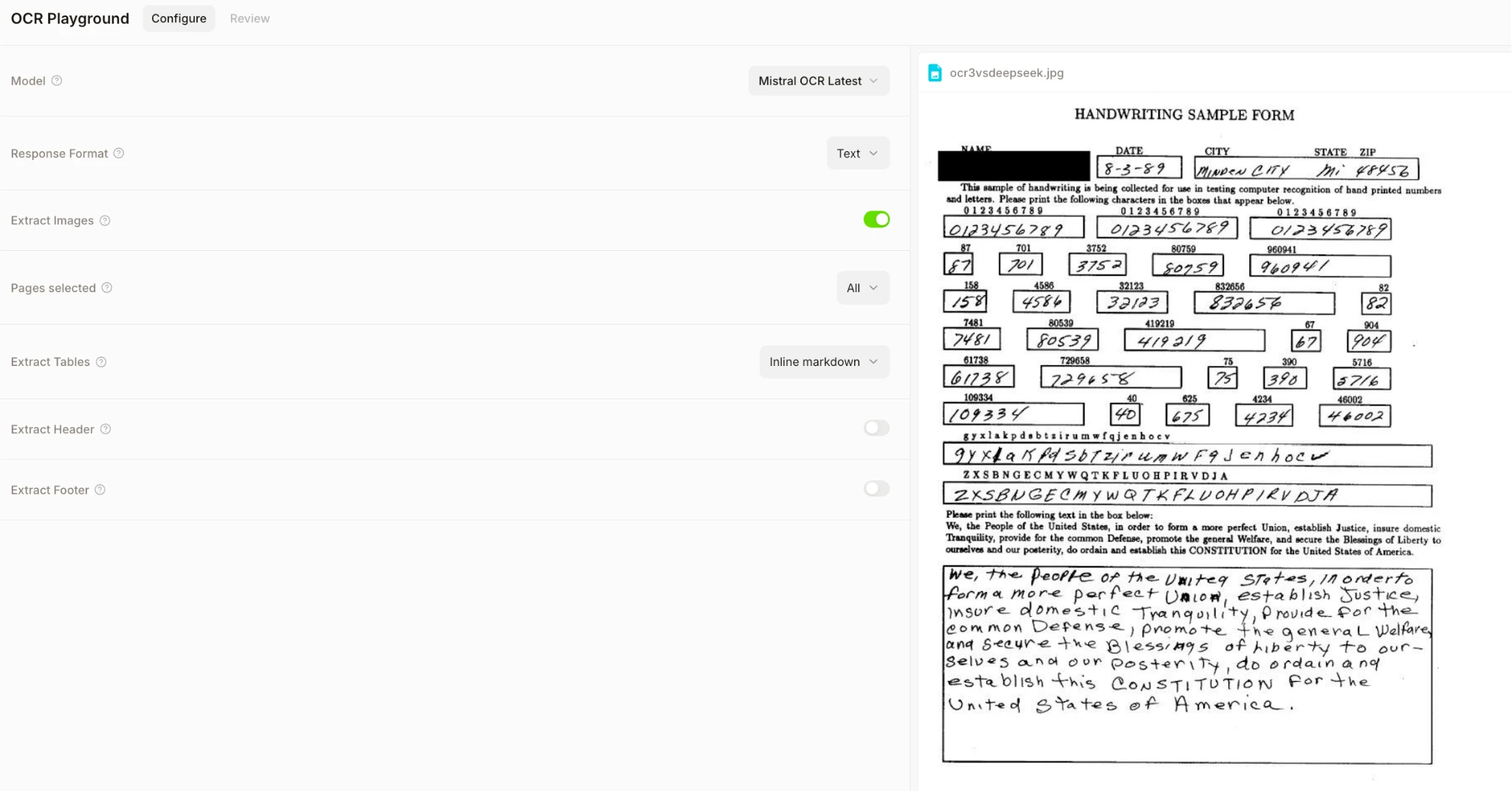
Output:
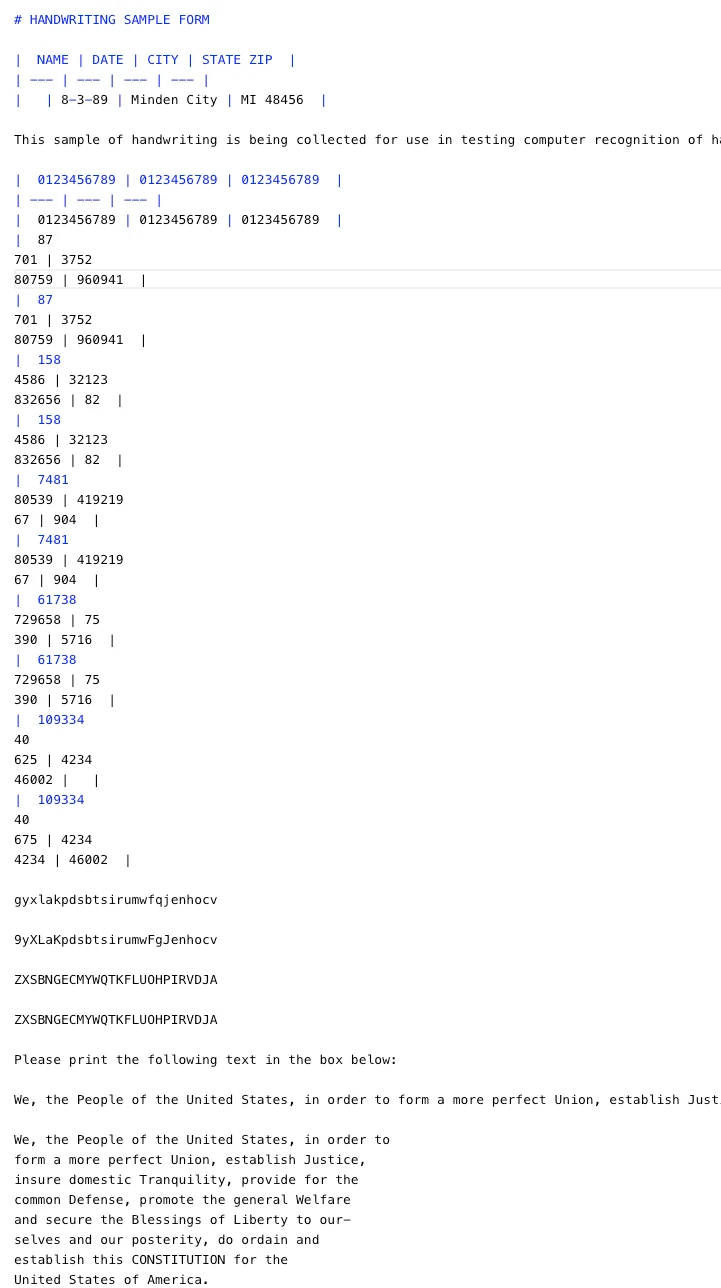
This result’s spectacular given the problem of the enter.
- Mistral OCR 3 accurately identifies the doc construction, headers, and most handwritten digits and textual content, changing a dense handwriting type into usable markdown.
- Some duplication and minor alignment points seem within the tables, which is predicted for heavy handwriting grids.
- General, it demonstrates sturdy handwriting recognition and format consciousness, making it appropriate for real-world type digitization with gentle post-processing
Deepseek OCR
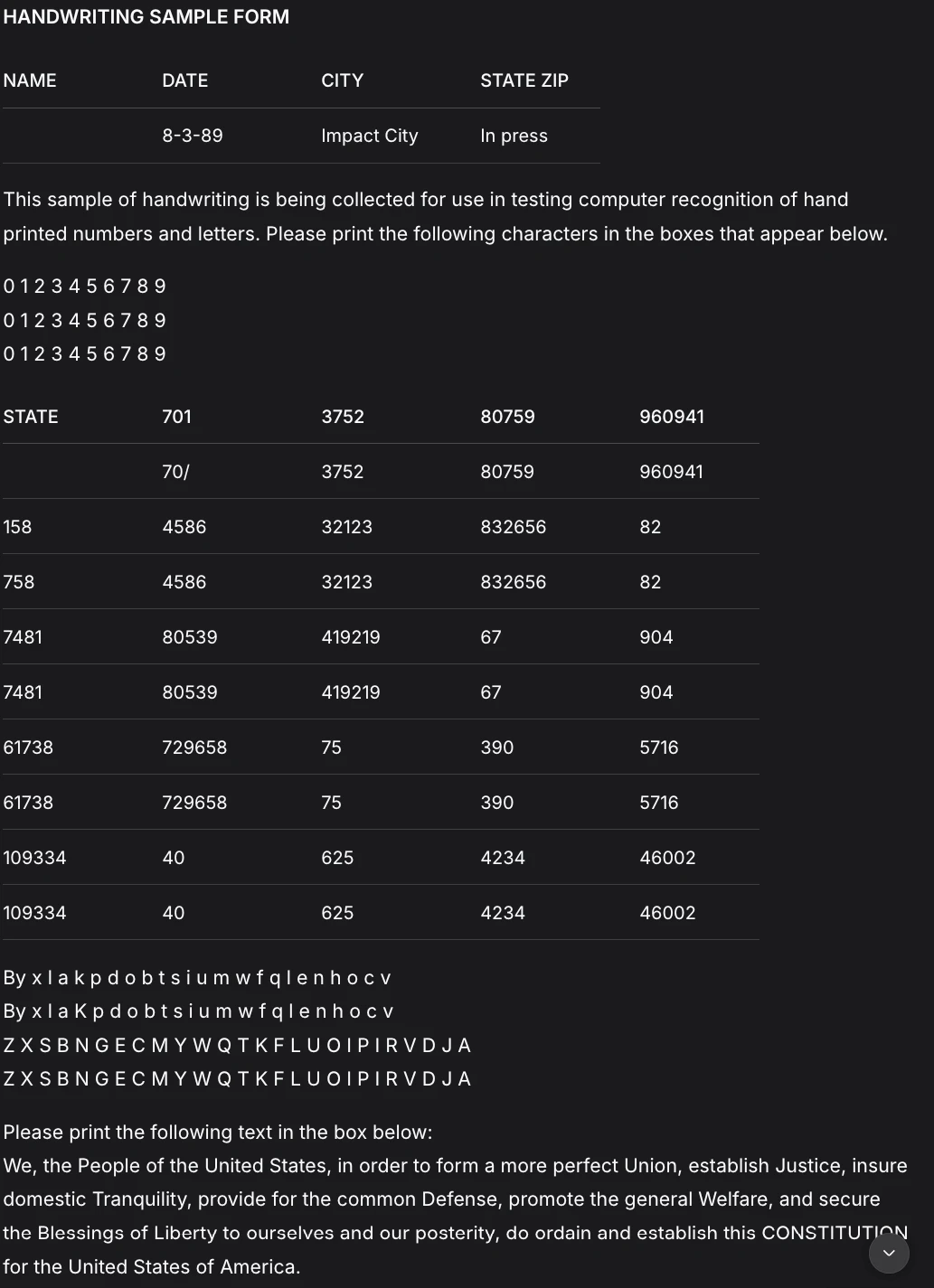
The end result has been beautified which makes it simpler to undergo than the earlier response. Listed here are few different issues that I seen in regards to the :
- DeepSeek OCR reveals strong handwriting recognition however struggles extra with semantic accuracy and format constancy.
- Key fields are misinterpreted, resembling “Metropolis” and “State ZIP”, and desk construction is much less trustworthy with incorrect headers and duplicated rows.
- Character-level recognition is first rate, however spacing, grouping, and area which means degrade beneath dense handwriting.
Consequence:
Mistral OCR 3 clearly outperforms DeepSeek OCR on this handwriting-heavy type. It preserves doc construction, area semantics, and desk alignment way more precisely, even beneath dense handwritten grids. DeepSeek OCR reads characters fairly nicely however breaks on format, headers, and area which means, resulting in greater cleanup effort. For real-world type digitization and automation, Mistral OCR 3 is the clear winner.
Which One Ought to You Select?
Choose Mistral OCR 3 in case you require a full OCR product that features a UI and a transparent OCR API. It’s optimum in case of high-fidelity and predictable SaaS price and valuation of desk reconstruction.
Choose DeepSeek-OCR when it’s required to be hosted on-premises or self-hosted. It offers the flexibleness and management of the inference course of to the groups which might be keen to regulate the operations. It’s doable that many groups will resort to the each: Mistral as the first pipeline and DeepSeek as a backup of delicate paperwork.
Conclusion
The construction and workflow turn out to be main considerations because of the modifications in Mistral OCR 3. The desk controls, JSON extraction annotations, and a playground have options resembling UI and might scale back growth time. It is without doubt one of the highly effective productizations of doc intelligence. DeepSeek-OCR gives one other manner. It considers OCR a compression drawback that’s involved with LLM, and gives customers with freedom of infrastructure. These two fashions display the long run separation of OCR expertise.
Continuously Requested Questions
A. Its key energy is that it concentrates on sustaining doc construction together with sophisticated tables and studying sequences, changing scanned paperwork to helpful info.
A. It has the potential of producing tables in HTML format, which has the added benefit of sustaining complicated information resembling merged cells and multi-row headers making certain better information integrity.
A. Sure, Doc AI Playground within the AI Studio of Mistral presents you add paperwork and experiment with the OCR options.
![]()
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Obsessed with GenAI, NLP, and making machines smarter (in order that they don’t change him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.





")
{kind=link}